23 Jul 2018 |
Java |
Collection
首先理解一下集合框架的整体设计,下图并没有包括与并发相关的集合,也没有map。
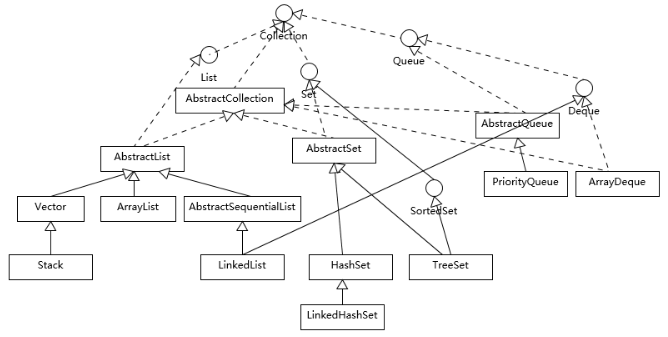
从上图可以看出Java集合是以Collection为接口,然后下面分为三大类:
- List:提供最基本的集合操作,元素可以重复
- Set:提供最基本的集合操作,元素不可以重复(不存在两个对象 equals 返回 true)
- Queue:实现队列操作,先进后出
List 细分为三种:
- ArrayList:使用数组实现,访问操作快(通过数组下标直接访问),修改操作慢(需要将部分数组整体后移);默认容量10,每次扩容50%。 ArrayList支持序列化。
- LinkedList:使用链表实现,访问操作慢(需要遍历),修改操作快(改变链表的指向)。
- Vector:使用数组实现的线程安全的
list。默认容量10,每次扩容增加一倍(在不指定增加容量系数的情况下)。Vector不支持序列化。
fail-fast
fail-fast 机制是java集合(Collection)中的一种错误机制。当多个线程对同一个集合的内容进行操作时,就可能会产生fail-fast事件。
例如:当某一个线程A通过iterator去遍历某集合的过程中,若该集合的内容被其他线程所改变了;那么线程A访问集合时,就会抛出java.util.ConcurrentModificationException异常,产生fail-fast事件。
在ArrayList中进行迭代是会执行 checkForComodification()。若 ==“modCount != expectedModCount”==,则抛出ConcurrentModificationException异常,产生fail-fast事件。
在CopyOnWriteArrayList中的add、set、remove等会改变原数组的方法中,都是==先copy一份原来的array==,再在copy数组上进行add、set、remove`操作,这就不影响COWIterator那份数组(迭代的数组)。
Map
map是以键值对的形式存储和操作数据的容器类型。
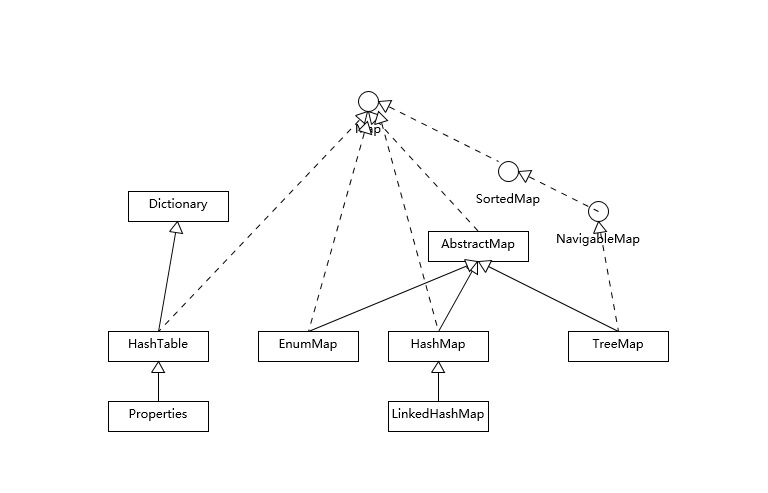
三个主要的map:
- Hashtable:线程安全,k-v不能为空
- HashMap:通用map,元素无序,k-v可以为空(在第一个位置),
hashCode()和equals()要一致,内部结构由数组和链表相结合(超过阈值,链表退化为树),
- TreeMap:基于红黑树的有序map。
- LinkedHashMap:继承HashMap,元素以输入的顺序输出,每次使用了的元素就放在最后,所以前面的就是最近很少使用的(
LinkedHashMap就是为LRU缓存而设计的,)。
参考资源:
21 Jul 2018 |
relation-extraction |
关系抽取是从一个句子中判断出这个句子里面两个实体之间的关系。
比如给定句子:
1 "The system as described above has its greatest application in an arrayed <e1>configuration</e1> of antenna <e2>elements</e2>."
Component-Whole(e2,e1)
Comment: Not a collection: there is structure here, organisation.
上面的句子是数据集 SemEval 2010 Task 8 数据集 中的一个训练集的实际样本,1表示第一条句子,<e1>configuration</e1> 是指明了实体一, <e2>elements</e2>是指明了实体二,Component-Whole(e2,e1)表明了两个实体之间的关系是Component-Whole关系。Comment是对句子的一些描述信息。
数据集SemEval 2010 Task 8中关系是9种,为了区别正反(Cause-Effect(e1,e2)与Cause-Effect(e2,e1)看作是两种关系)和其他(other,有些句子中的实体关系不是给定的关系)一共是19种关系:
(1) Cause-Effect
(2) Instrument-Agency
(3) Product-Producer
(4) Content-Container
(5) Entity-Origin
(6) Entity-Destination
(7) Component-Whole
(8) Member-Collection
(9) Message-Topic
那么我们要根据训练集训练出的模型对句子中的关系进行预测。
A few days before the service, Tom Burris had thrown into Karen's <e1>casket</e1> his wedding <e2>ring</e2>.
上面就是测试例子,请给出两个实体之间的关系。这就是我们要做的关系抽取,现在的关系抽取都是有监督的关系抽取,还有半监督的,还有无监督的(开放域的实体关系抽取),这在深度学习中还是研究热点。
接下来就进入正文:
Relation classification via convolutional deep neural network
【Zeng, D & Liu, K & Lai, S & Zhou, G & Zhao, J. (2014). Relation classification via convolutional deep neural network. the 25th International Conference on Computational Linguistics: Technical Papers. 2335-2344.
】这篇文章使用了比较经典的CNN的结构,包含了池化层,进行关系抽取。
论文成果:
- 1.不使用复杂的NLP(不需要词性标记与句法分析)进行关系抽取
- 2.使用位置特征来表示距离
- 3.在SemEval-2010 Task 8数据集进行了实验,与传统方法进行了对比
网络架构:
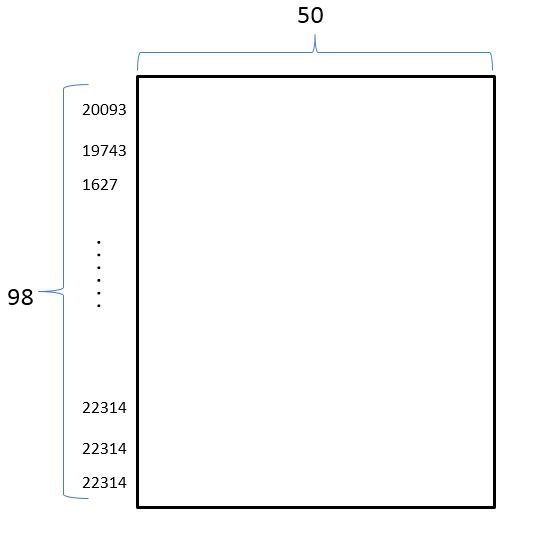
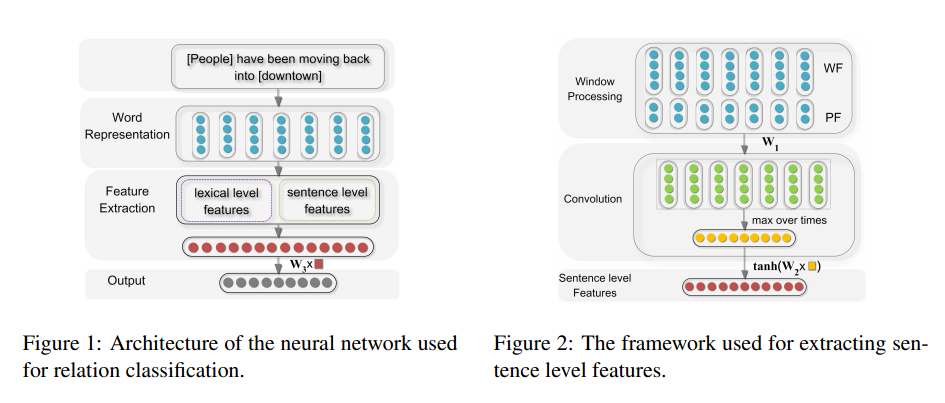 首先获取全部词构成一个字典,然后把句子中的词转化为对应的ID(一个整数表示),接着再把这些词表示为一个向量,并统一设置句子长度,那么一个句子就被转化为98 x 50 的向量矩阵。
首先获取全部词构成一个字典,然后把句子中的词转化为对应的ID(一个整数表示),接着再把这些词表示为一个向量,并统一设置句子长度,那么一个句子就被转化为98 x 50 的向量矩阵。
原始训练文件:
1"The system as described above has its greatest application in an arrayed <e1>configuration</e1> of antenna <e2>elements</e2>."
Component-Whole(e2,e1)
Comment: Not a collection: there is structure here, organisation.
处理后的文件:
3 12 12 15 15 the system as described above has its greatest application in an arrayed configuration of antenna elements
3 表示关系 Component-Whole(e2,e1)
12 表示实体1的位置
15 表示实体2的位置
一个句子中的所有词用数字表示:
Raw_Example(label=3, entity1=PosPair(first=12, last=12), entity2=PosPair(first=15, last=15), sentence=[20093, 19743, 1627, 5836, 587, 9402, 10812, 9031, 1434, 10201, 1210, 1583, 4607, 13862, 1326, 6828])
最终一个句子被表示为一个二维矩阵(也就是word2vec):
文中的亮点操作1是:
词特征:考虑了实体的上下文词
句子:
"The system as described above has its greatest application in an arrayed <e1>configuration</e1> of antenna <e2>elements</e2>."
实体1的词特征:实体1的上一个词与下一个词configuration上一个词 arrayed ,下一个词of
实体2的词特征:实体2的上一个词与下一个词elements上一个词antenna ,下一个词<pad>(没有下一个词用特殊词<pad>来表示)
用数字表示:
entity1_context:[4607, 1583, 13862]
entity1_context:[6828, 1326, 22314]
lexical_feature:[4607, 1583, 13862, 6828, 1326, 22314]
最终词特征的向量化表示就是:
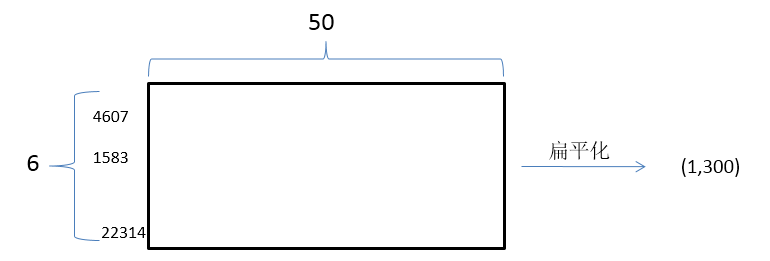
文中的亮点操作2是:
位置特征:每个词离实体的相对位置

数字化表示就是:
entity1_posittion: [49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64 ,……, 122]
entity2_posittion: [46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61 ,……, 122]
向量化表示就是:

神经网络输入:词向量结合句子特征与位置特征构成卷积神经网络的最终输入
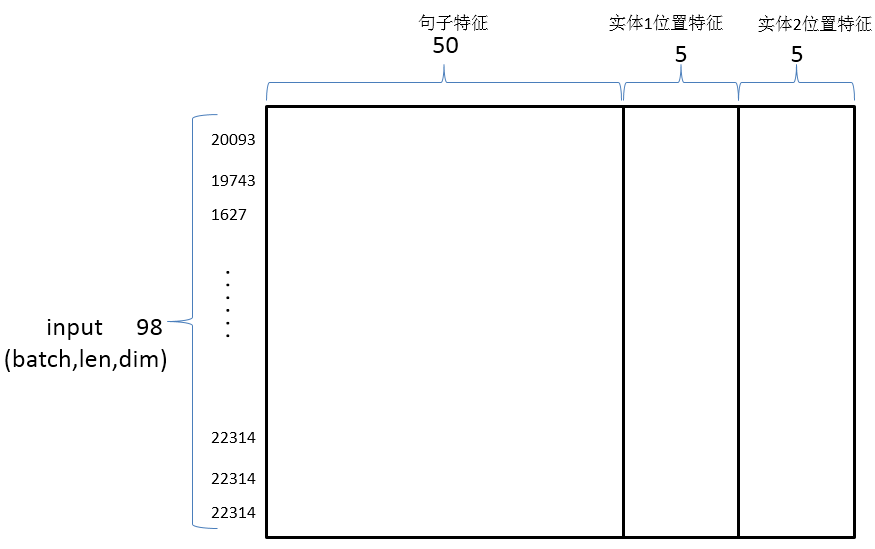
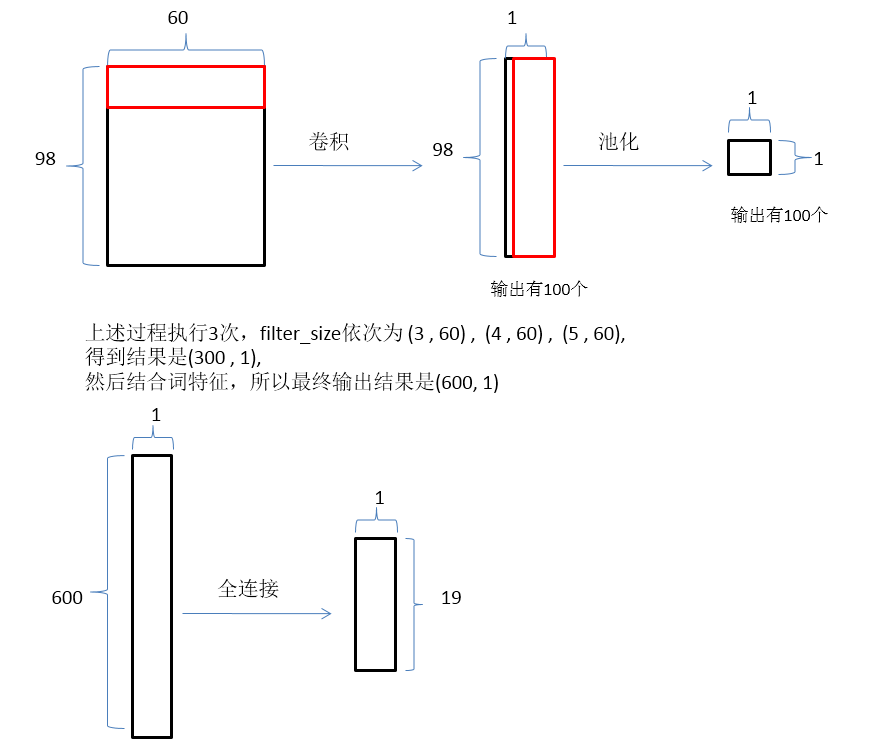
神经网络前向传播:
实验结果:
 从实验结果可以看出,用作者提出的神经网络结构进行关系抽取的效果比传统的方法要好。
从实验结果可以看出,用作者提出的神经网络结构进行关系抽取的效果比传统的方法要好。
15 Jul 2018 |
relation-extraction |
这篇文章主要梳理了基于深度学习的关系抽取的研究进展,列出了主要的文章,后续会再慢慢解读。
1 CNN:这篇文章是第一次使用CNN来做关系分类,使用的CNN结构也十分简单【[1] Liu C Y, Sun W B, Chao W H, et al. Convolution Neural Network for Relation Extraction[C]// International Conference on Advanced Data Mining and Applications. Springer, Berlin, Heidelberg, 2013:231-242.
】。
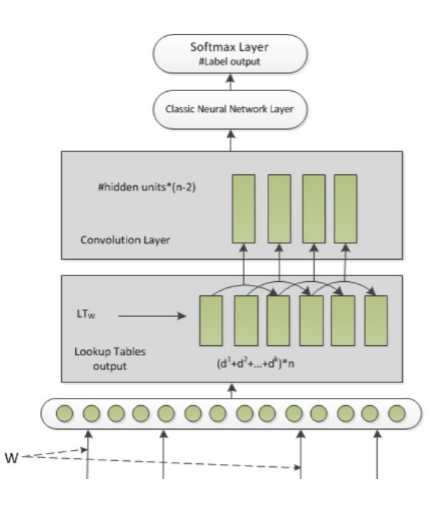
2 CNN+POOling:这篇文章使用了比较经典的CNN的结构,包含了Pooling层,以及设计了Position Features。【Zeng, D & Liu, K & Lai, S & Zhou, G & Zhao, J. (2014). Relation classification via convolutional deep neural network. the 25th International Conference on Computational Linguistics: Technical Papers. 2335-2344.
】
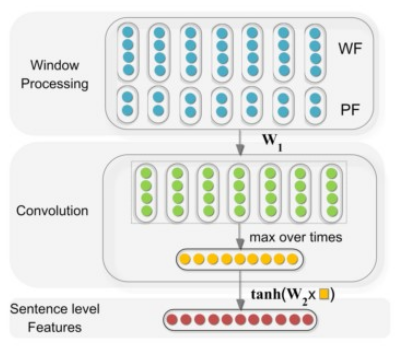
3 Multi-sized CNN :在卷积阶段使用多个尺寸的卷积核【Nguyen T H, Grishman R. Relation Extraction: Perspective from Convolutional Neural Networks[C]// The Workshop on Vector Space Modeling for Natural Language Processing. 2015:39-48.
】
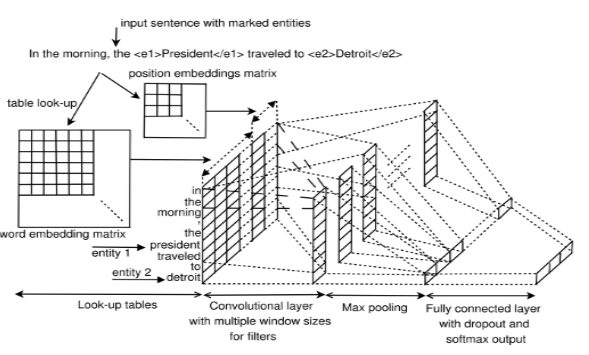
4 CR-CNN:使用新的损失函数,不再使用softmax+cross-entropy的方式【Dos Santos, Cicero & Xiang, Bing & Zhou, Bowen. (2015). Classifying Relations by Ranking with Convolutional Neural Networks. Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing. 1. 10.3115/v1/P15-1061.
】
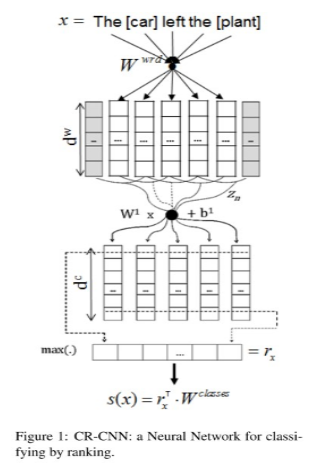
5 RNN:这篇文章不再使用CNN作为基本结构,而是开始尝试RNN。【Zhang D, Wang D. Relation Classification via Recurrent Neural Network[J]. Computer Science, 2015.
】
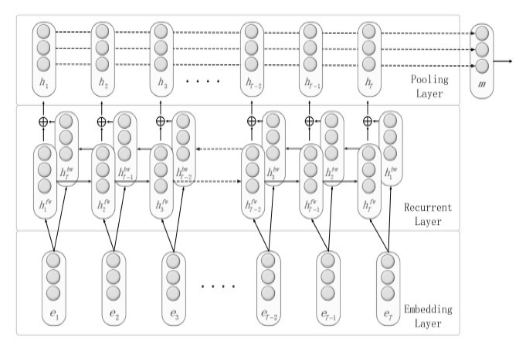
6 BiLSTM Attention:这篇文章是基于RNN对句子建模,在上一篇RNN的基础上
做了一点改进,使用标准的的Attention + BiLSTM【Zhou P, Shi W, Tian J, et al. Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification[C]// Meeting of the Association for Computational Linguistics. 2016:207-212.
】
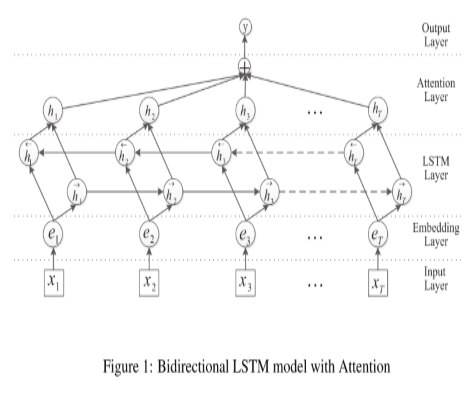
7 Multi-Level Attention CNN:文中设计了相对复杂的两层Attention机制。【Wang L, Cao Z, Melo G D, et al. Relation Classification via Multi-Level Attention CNNs[C]// Meeting of the Association for Computational Linguistics. 2016:1298-1307.
】
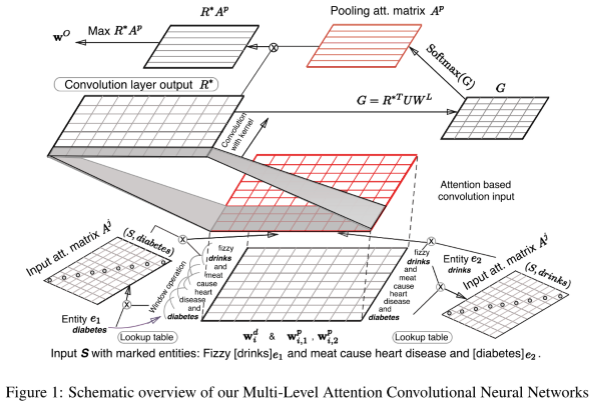
8 PCNN:使用远程监督可以自动标注训练样本,不再需要手动标注数据。
【Zeng D, Liu K, Chen Y, et al. Distant Supervision for Relation Extraction via Piecewise Convolutional Neural Networks[C]// Conference on Empirical Methods in Natural Language Processing. 2015:1753-1762.
】
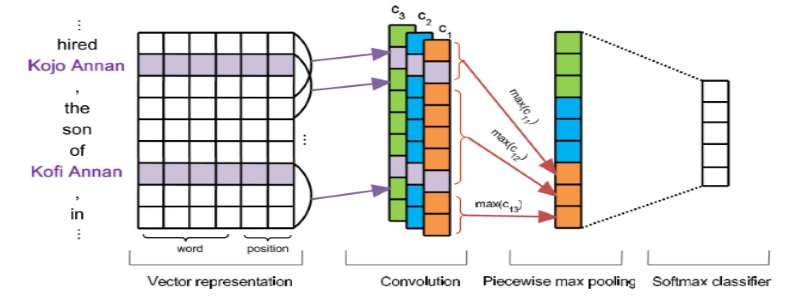
9 APCNN+D:这篇文章的贡献主要在从KG中引入额外的实体描述信息,加强embedding的学习【Liu, K.; He, S.; and Zhao, J. 2017. Distant supervision for relation extraction with sentence-level attention and entity descriptions. In AAAI, 3060–3066.
】
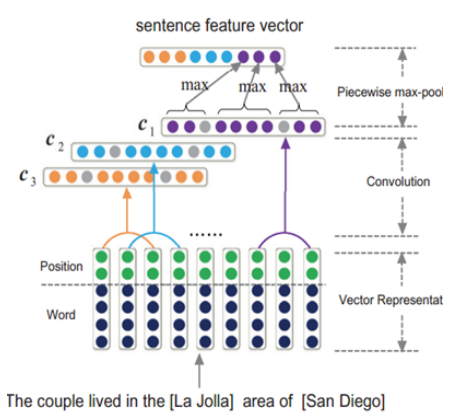
10 ACL2017 outstanding paper:
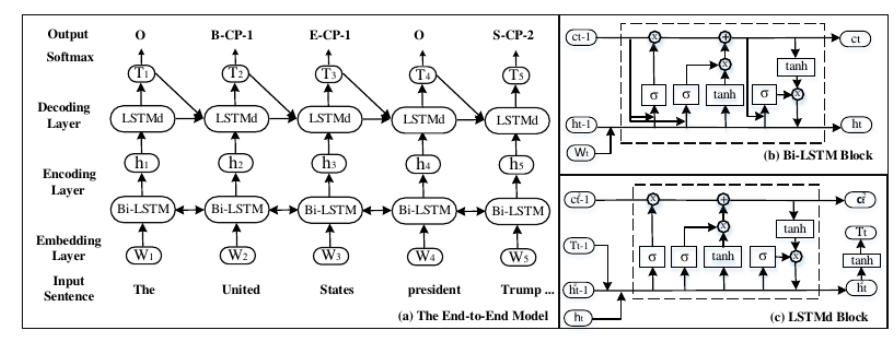
文章基于新的标注方法,研究了基于LSTM的end-to-end模型来解决联合抽取实体和关系的任务【Zheng S, Wang F, Bao H, et al. Joint Extraction of Entities and Relations Based on a Novel Tagging Scheme[J]. 2017:1227-1236.
】
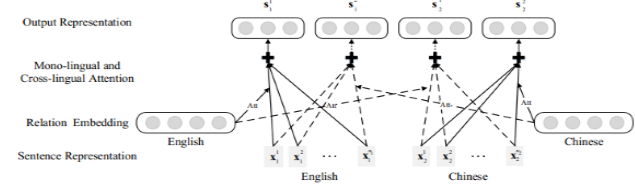
11 MNRE : 该文章提出了多语言Attention关系提取方法,以考虑多种语言之间的模式一致性和互补性。 结果表明,其模型可以有效地建立语言之间的关系模式,实现很好地效果。【Lin Y, Liu Z, Sun M. Neural Relation Extraction with Multi-lingual Attention[C]// Meeting of the Association for Computational Linguistics. 2017:34-43.
】
参考文章:
基于深度学习的关系抽取