06 Aug 2018 |
NLP |
HanLP词性标注集
HanLP使用的HMM词性标注模型训练自2014年人民日报切分语料,随后增加了少量98年人民日报中独有的词语。所以,HanLP词性标注集兼容《ICTPOS3.0汉语词性标记集》,并且兼容《现代汉语语料库加工规范——词语切分与词性标注》。一共148种。
HanLP词性标注集
| 符号 |
意义 |
| a |
形容词 |
| ad |
副形词 |
| ag |
形容词性语素 |
| al |
形容词性惯用语 |
| an |
名形词 |
| b |
区别词 |
| begin |
仅用于始##始 |
| bg |
区别语素 |
| bl |
区别词性惯用语 |
| c |
连词 |
| cc |
并列连词 |
| d |
副词 |
| dg |
辄,俱,复之类的副词 |
| dl |
连语 |
| e |
叹词 |
| end |
仅用于终##终 |
| f |
方位词 |
| g |
学术词汇 |
| gb |
生物相关词汇 |
| gbc |
生物类别 |
| gc |
化学相关词汇 |
| gg |
地理地质相关词汇 |
| gi |
计算机相关词汇 |
| gm |
数学相关词汇 |
| gp |
物理相关词汇 |
| h |
前缀 |
| i |
成语 |
| j |
简称略语 |
| k |
后缀 |
| l |
习用语 |
| m |
数词 |
| mg |
数语素 |
| Mg |
甲乙丙丁之类的数词 |
| mq |
数量词 |
| n |
名词 |
| nb |
生物名 |
| nba |
动物名 |
| nbc |
动物纲目 |
| nbp |
植物名 |
| nf |
食品,比如“薯片” |
| ng |
名词性语素 |
| nh |
医药疾病等健康相关名词 |
| nhd |
疾病 |
| nhm |
药品 |
| ni |
机构相关(不是独立机构名) |
| nic |
下属机构 |
| nis |
机构后缀 |
| nit |
教育相关机构 |
| nl |
名词性惯用语 |
| nm |
物品名 |
| nmc |
化学品名 |
| nn |
工作相关名词 |
| nnd |
职业 |
| nnt |
职务职称 |
| nr |
人名 |
| nr1 |
复姓 |
| nr2 |
蒙古姓名 |
| nrf |
音译人名 |
| nrj |
日语人名 |
| ns |
地名 |
| nsf |
音译地名 |
| nt |
机构团体名 |
| ntc |
公司名 |
| ntcb |
银行 |
| ntcf |
工厂 |
| ntch |
酒店宾馆 |
| nth |
医院 |
| nto |
政府机构 |
| nts |
中小学 |
| ntu |
大学 |
| nx |
字母专名 |
| nz |
其他专名 |
| o |
拟声词 |
| p |
介词 |
| pba |
介词“把” |
| pbei |
介词“被” |
| q |
量词 |
| qg |
量词语素 |
| qt |
时量词 |
| qv |
动量词 |
| r |
代词 |
| rg |
代词性语素 |
| Rg |
古汉语代词性语素 |
| rr |
人称代词 |
| ry |
疑问代词 |
| rys |
处所疑问代词 |
| ryt |
时间疑问代词 |
| ryv |
谓词性疑问代词 |
| rz |
指示代词 |
| rzs |
处所指示代词 |
| rzt |
时间指示代词 |
| rzv |
谓词性指示代词 |
| s |
处所词 |
| t |
时间词 |
| tg |
时间词性语素 |
| u |
助词 |
| ud |
助词 |
| ude1 |
的 底 |
| ude2 |
地 |
| ude3 |
得 |
| udeng |
等 等等 云云 |
| udh |
的话 |
| ug |
过 |
| uguo |
过 |
| uj |
助词 |
| ul |
连词 |
| ule |
了 喽 |
| ulian |
连 (“连小学生都会”) |
| uls |
来讲 来说 而言 说来 |
| usuo |
所 |
| uv |
连词 |
| uyy |
一样 一般 似的 般 |
| uz |
着 |
| uzhe |
着 |
| uzhi |
之 |
| v |
动词 |
| vd |
副动词 |
| vf |
趋向动词 |
| vg |
动词性语素 |
| vi |
不及物动词(内动词) |
| vl |
动词性惯用语 |
| vn |
名动词 |
| vshi |
动词“是” |
| vx |
形式动词 |
| vyou |
动词“有” |
| w |
标点符号 |
| wb |
百分号千分号,全角:% ‰ 半角:% |
| wd |
逗号,全角:, 半角:, |
| wf |
分号,全角:; 半角: ; |
| wh |
单位符号,全角:¥ $ £ ° ℃ 半角:$ |
| wj |
句号,全角:。 |
| wky |
右括号,全角:) 〕 ] } 》 】 〗 〉 半角: ) ] { > |
| wkz |
左括号,全角:( 〔 [ { 《 【 〖 〈 半角:( [ { < |
| wm |
冒号,全角:: 半角: : |
| wn |
顿号,全角:、 |
| wp |
破折号,全角:—— -- ——- 半角:— —- |
| ws |
省略号,全角:…… … |
| wt |
叹号,全角:! |
| ww |
问号,全角:? |
| wyy |
右引号,全角:” ’ 』 |
| wyz |
左引号,全角:“ ‘ 『 |
| x |
字符串 |
| xu |
网址URL |
| xx |
非语素字 |
| y |
语气词(delete yg) |
| yg |
语气语素 |
| z |
状态词 |
| zg |
状态词 |
《人民日报》标注语料库
04 Aug 2018 |
NLP |
正向最大匹配(Maximum Match Method,MM法)的基本思想为:一开始以词典最大词长度len进行分词,如果能够在句子中分出词典中存在的词,那么就匹配成功,继续进行后面的分词,一开始还是以词典最大词进行分词;如果没有匹配成功,那么就减len-1,继续匹配。
比如我们现在有个词典,最长词的长度为5,词典中存在“南京市长”和“长江大桥”两个词。现采用正向最大匹配对句子“南京市长江大桥”进行分词,那么首先从句子中取出前五个字“南京市长江”,发现词典中没有该词,于是缩小长度,取前4个字“南京市长”,词典中存在该词,于是该词被确认切分。再将剩下的“江大桥”按照同样方式切分,得到“江”“大桥”,最终分为“南京市长”“江”“大桥”3个词。
逆向最大匹配(Maximum Match Method,MM法)的基本思想为:一开始以词典最大词长度len进行分词,但是是从句子的末端开始,如果能够在句子中分出词典中存在的词,那么就匹配成功,继续进行后面的分词,一开始还是以词典最大词进行分词;如果没有匹配成功,那么就减len-1,继续匹配。
比如之前的“南京市长江大桥”,按照逆向最大匹配,最终得到“南京市”“长江大桥”。
双向最大匹配法(Bi-directction Matching method)是将正向最大匹配法得到的分词结果和逆向最大匹配法得到的结果进行比较,然后按照最大匹配原则,选取词数切分最少的作为结果。
比如之前的“南京市长江大桥”,就会选用逆向最大匹配
class SegmentMatch(object):
def __init__(self, dict_path):
self.dictionary = set()
self.maximum = 0
#加载词典
with open(dict_path, 'r', encoding='utf-8') as f:
for line in f:
line = line.strip()
if not line:
continue
self.dictionary.add(line)
if len(line) > self.maximum:
self.maximum = len(line)
#逆向最大匹配
def reverseMM(self, text):
result = []
index = len(text)
while index > 0:
for size in range(self.maximum, 0, -1):
if index - size < 0:
continue
piece = text[(index - size):index]
if piece in self.dictionary:
result.append(piece)
index = index - size
break
return result[::-1] #反向
##正向最大匹配
def mm(self, text):
result = []
index = 0
while index < len(text):
for size in range(self.maximum, 0, -1):
if index + size > len(text):
continue
piece = text[index : (index+size)]
if piece in self.dictionary:
result.append(piece)
index = index + size
break
return result
def main():
text = "南京市长江大桥"
seg = SegmentMatch('E:/NLP/mytest/imm_dic.utf8')
result1 = seg.reverseMM(text)
result2 = seg.mm(text)
if len(result1) < len(result2): #双向匹配就是选择正向逆向匹配结果所含分词最小的
print(result1)
else:
print(result2)
if __name__ == '__main__':
main()
参考资料:
《Python自然语言处理实战:核心技术与算法》 — 涂铭 刘祥 刘树春
29 Jul 2018 |
relation-extraction |
关系抽取是从一个句子中判断出这个句子里面两个实体之间的关系。
比如给定句子:
1 "The system as described above has its greatest application in an arrayed <e1>configuration</e1> of antenna <e2>elements</e2>."
Component-Whole(e2,e1)
Comment: Not a collection: there is structure here, organisation.
上面的句子是数据集SemEval 2010 Task 8 数据集
中的一个训练集的实际样本,1表示第一条句子,<e1>configuration</e1> 是指明了实体一, <e2>elements</e2>是指明了实体二,Component-Whole(e2,e1)表明了两个实体之间的关系是Component-Whole关系。Comment是对句子的一些描述信息。
数据集SemEval 2010 Task 8中关系是9种,为了区别正反(Cause-Effect(e1,e2)与Cause-Effect(e2,e1)看作是两种关系)和其他(other,有些句子中的实体关系不是给定的关系)一共是19种关系:
(1) Cause-Effect
(2) Instrument-Agency
(3) Product-Producer
(4) Content-Container
(5) Entity-Origin
(6) Entity-Destination
(7) Component-Whole
(8) Member-Collection
(9) Message-Topic
那么我们要根据训练集训练出的模型对句子中的关系进行预测。
A few days before the service, Tom Burris had thrown into Karen's <e1>casket</e1> his wedding <e2>ring</e2>.
上面就是测试例子,请给出两个实体之间的关系。这就是我们要做的关系抽取,现在的关系抽取都是有监督的关系抽取,还有半监督的,还有无监督的(开放域的实体关系抽取),这在深度学习中还是研究热点。
接下来就进入正文:
【Nguyen T H, Grishman R. Relation Extraction: Perspective from Convolutional Neural Networks[C]// The Workshop on Vector Space Modeling for Natural Language Processing. 2015:39-48.
】
文章中主要使用的方法是多核卷积神经网络来进行关系抽取。
论文成果:
- 不使用复杂的NLP进行关系抽取
- 使用位置特征来表示距离
- 使用多核卷积构建网络架构
- 在SemEval-2010 Task 8数据集进行了实验,取得了很好的结果
论文架构:
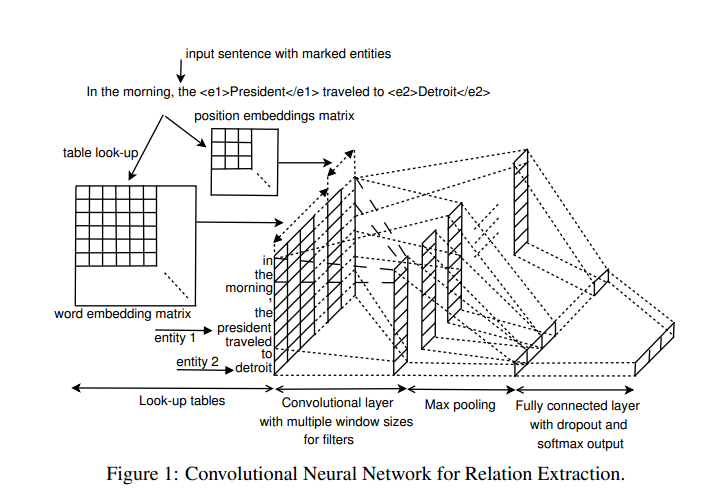
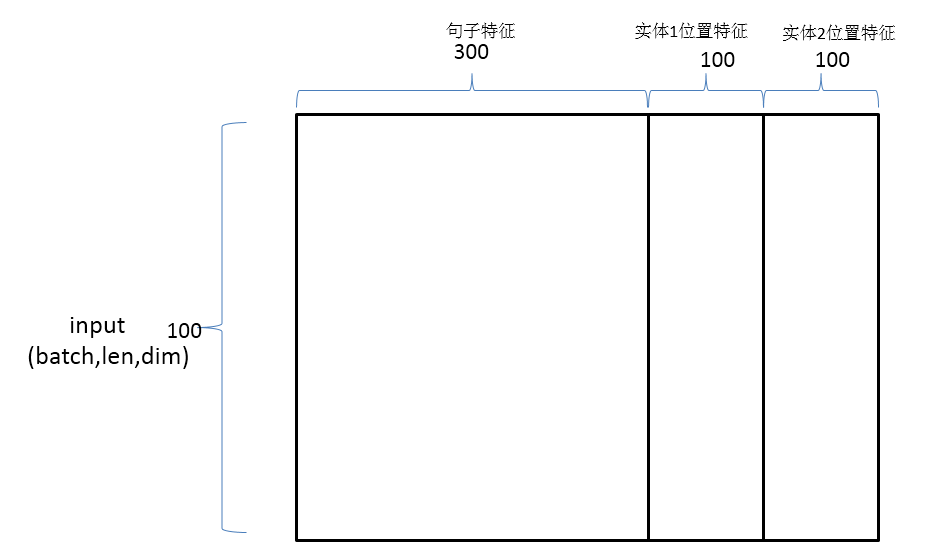
神经网络输入:
结合句子特征与位置特征构成卷积神经网络的最终输入
神经网络前向传播:
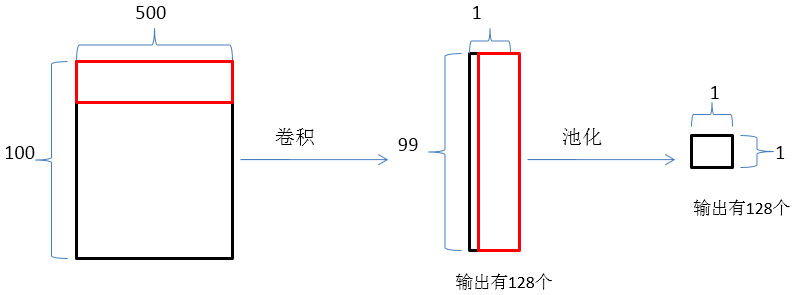
上述过程执行4次,filter_size依次为(2 , 500) , (3 , 500) , (4 , 500) , (5 , 500),
得到结果是(512 , 1),然后进行全连接。
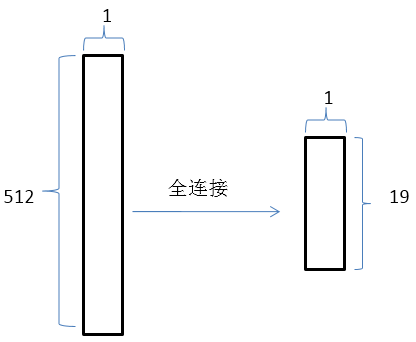
最终的实验结果F1值达到82.8