15 Sep 2018 |
NLP |
组织机构的识别是在地名识别与人名识别之后进行的,它所使用的方式与地名、人名识别使用的方法是一样的,也是粗分句子、组织机构角色标注、选择最优角色、模式识别。
假设我现在有一个句子是:
我们如何找出对它进行分词并找出里面的组织机构名称呢?
粗分句子
对原句使用维特比算法进行初步切分,得到如下结果:

然后进行人名地名的识别,得到如下结果:
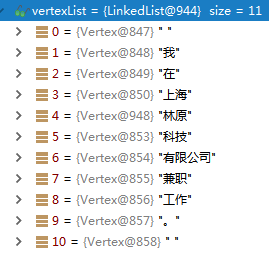
我们可以看到,经过上面的人名地名识别步骤,它识别出了林原是一个人名。好了,至此前面的操作我们认为都是粗分句子的步骤,接下来,是在粗分句子的基础之上进行真正的组织机构识别操作。
组织机构角色标注
这里的组织机构角色标注与之前的人名角色标注,地名角色标注所表示的意义是一样的,都是自定义的,为组织机构,地名,人名的识别打基础。那么,这里的组织机构角色标注集是这样的:
public enum NT
{
/**
* 上文 [参与]亚太经合组织的活动
*/
A,
/**
* 下文 中央电视台[报道]
*/
B,
/**
* 连接词 北京电视台[和]天津电视台
*/
X,
/**
* 特征词的一般性前缀 北京[电影]学院
*/
C,
/**
* 特征词的译名性前缀 美国[摩托罗拉]公司
*/
F,
/**
* 特征词的地名性前缀 交通银行[北京]分行
*/
G,
/**
* 特征词的机构名前缀 [中共中央]顾问委员会
*/
H,
/**
* 特征词的特殊性前缀 [华谊]医院
*/
I,
/**
* 特征词的简称性前缀 [巴]政府
*/
J,
/**
* 整个机构 [麦当劳]
*/
K,
/**
* 方位词
*/
L,
/**
* 数词 公交集团[五]分公司
*/
M,
/**
* 单字碎片
*/
P,
/**
* 符号
*/
W,
/**
* 机构名的特征词 国务院侨务[办公室]
*/
D,
/**
* 非机构名成份
*/
Z,
/**
* 句子的开头
*/
S
}
那么,如何对刚才的粗分结果进行角色标注呢?最主要的方式还是利用词典进行匹配。
组织机构的词典是这样的:
······
褐山 I 2
襄安 I 1
襄汾 I 1
西 L 100 A 20 B 15 X 1
西三旗 I 4
西乡 I 12
西二环 A 1
西侧 B 8 A 2
西元 I 1
······
每一行的规则是:词 词性A 词性A的词频 词性B 词性B的词频
比如西侧 B 8 A 2表示词西侧作为词性B(组织机构上文)在语料中出现的次数是8次,作为词性A(组织机构上文)在语料中出现的次数是2次。
那么,最后得到的角色标注结果就是:

选择最优角色
刚才的标注结果中,词可能有多个角色,我们需要选择出最优的角色,此处可以使用维特比算法选择最优角色,得到的结果是:

模式匹配
各个词选择了最优的角色,构成了一个词串SAAGFCDBABS,现在我们要做的事情就是给定一些模式,如何在现在的词串中找出给定的模式,这又是一个多模式匹配问题,和之前一样,采用AC自动机来解决这个问题。另外,这里的模式非常多,我在这里只是列出一部分:
......
GJGFJCD
GJGJCD
GJGJCJCD
GJGJCKDGD
GJGMCCD
GJGPCCCD
GJGPD
......
模式当然都是自己定义的,根据角色标注集,其中那些可以组成一个组织机构名,就把它写成一种模式。
在我们现在的字符串中SAAGFCDBABS,根据AC自动机进行多模式匹配,最终找出的模式有GFCD,FCD,CD。这三个模式分别对应的词组成的机构名称是上海林原科技有限公司, 林原科技有限公司,科技有限公司。
那么现在我们的分词结果可能是:
0:[ ]
1:[我]
2:[在, 在]
3:[上海, 上海林原科技有限公司, 上海]
4:[海]
5:[林原, 林原科技有限公司]
6:[原]
7:[科技, 科技有限公司]
8:[]
9:[有限公司]
10:[]
11:[]
12:[]
13:[兼, 兼职]
14:[]
15:[工作]
16:[]
17:[。]
18:[ ]
所以,再一次使用维特比算法求解,得到最优结果是:
[我, 在, 上海, 林原科技有限公司, 兼职, 工作。]
参考文献:
09 Sep 2018 |
NLP |
地名的识别与人名的识别所用的方法是一样的,只是所用的词典与模式不同。在这篇文章中【基于层叠隐马尔可夫模型的中文命名实体识别】,也有详细的说明。
地名识别主要步骤:
- 粗分句子
- 地名词性标注
- 找出最有可能的词性
- 模式匹配
现在,我有一个句子,如何识别出其中的地名呢?
蓝翔给宁夏固原市彭阳县红河镇黑牛沟村捐赠了挖掘机。
首先,用简单的分词方法(比如:维特比分词),对句子进行初步的划分,得到如下的结果:
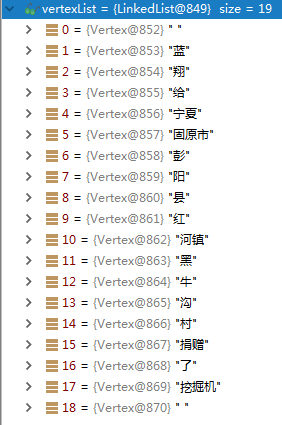
然后,使用自定义词典,对粗分结果进一步匹配,得到如下结果:
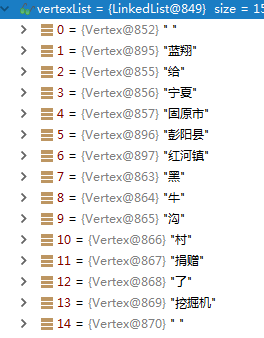
可以看到,通过自定义词典已经识别出了一些地名 彭阳县,红河镇,所以字典质量是非常重要的,但是字典又无法收录全部的地名,那么我们还是需要一些具体的方法去识别地名。
地名词性标注
地名词性标注是在对句子分词的基础之上进行的,对每个词进行地名词性的标注,这个过程是如何完成的呢?当然还是大家所熟悉的方法–通过地名词典匹配。地名词典大概是这样的:
......
日 A 146 C 46 B 27 D 14 X 1
日方 A 3
日晒 B 1
日本 G 10805
日本国 A 7
日渐 B 4
日照 G 58
日益 B 28
日程 B 1
日耳曼 G 27
......
这个词典的格式是:词 词性1 词性1的频次 词性2 词性2的频次
它这里用的标签是自己定义的:
/**
* 地名角色标签
*
* @author hankcs
*/
public enum NS
{
/**
* 地名的上文 我【来到】中关园
*/
A,
/**
* 地名的下文刘家村/和/下岸村/相邻
*/
B,
/**
* 中国地名的第一个字
*/
C,
/**
* 中国地名的第二个字
*/
D,
/**
* 中国地名的第三个字
*/
E,
/**
* 其他整个的地名
*/
G,
/**
* 中国地名的后缀海淀/区
*/
H,
/**
* 连接词刘家村/和/下岸村/相邻
*/
X,
/**
* 其它非地名成分
*/
Z,
/**
* 句子的开头
*/
S,
}
那么词典中的 日本 G 10805 这个就表示词日本作为地名词性G( 其他整个的地名)在整个语料中出现的次数是10805词。
通过上面的词典和角色标签,我们得到了地名词性标注如下:

找出最有可能的词性
通过上面的步骤得到的每个词的词性,但是我们需要找出最有可能的词性,这如何做到呢?作者使用了维特比算法解决了这个问题。维特比的核心思想是:局部最优达到全局最优。
/**
* 标准版的Viterbi算法,查准率高,效率稍低
*
* @param roleTagList 观测序列
* @param transformMatrixDictionary 转移矩阵
* @param <E> EnumItem的具体类型
* @return 预测结果
*/
public static <E extends Enum<E>> List<E> computeEnum(List<EnumItem<E>> roleTagList, TransformMatrixDictionary<E> transformMatrixDictionary)
{
int length = roleTagList.size() - 1;
List<E> tagList = new ArrayList<E>(roleTagList.size());//存放最优标签
double[][] cost = new double[2][]; // 滚动数组
Iterator<EnumItem<E>> iterator = roleTagList.iterator();
EnumItem<E> start = iterator.next();
E pre = start.labelMap.entrySet().iterator().next().getKey();
// 第一个是确定的
tagList.add(pre);
// 第二个也可以简单地算出来
Set<E> preTagSet;
{
EnumItem<E> item = iterator.next();
cost[0] = new double[item.labelMap.size()];
int j = 0;
for (E cur : item.labelMap.keySet())
{
cost[0][j] = transformMatrixDictionary.transititon_probability[pre.ordinal()][cur.ordinal()] - Math.log((item.getFrequency(cur) + 1e-8) / transformMatrixDictionary.getTotalFrequency(cur));
++j;//计算每次转移的代价cost(取频率的负对数,所以cost越小越好)
}
preTagSet = item.labelMap.keySet();
}
// 第三个开始复杂一些
for (int i = 1; i < length; ++i)
{
int index_i = i & 1;//用于滚动数组
int index_i_1 = 1 - index_i;//用于滚动数组
EnumItem<E> item = iterator.next();
cost[index_i] = new double[item.labelMap.size()];
double perfect_cost_line = Double.MAX_VALUE;
int k = 0;
Set<E> curTagSet = item.labelMap.keySet();
for (E cur : curTagSet)
{
cost[index_i][k] = Double.MAX_VALUE;
int j = 0;
for (E p : preTagSet)
{
double now = cost[index_i_1][j] + transformMatrixDictionary.transititon_probability[p.ordinal()][cur.ordinal()] - Math.log((item.getFrequency(cur) + 1e-8) / transformMatrixDictionary.getTotalFrequency(cur));//计算每次转移的代价cost(取频率的负对数,所以cost越小越好)
if (now < cost[index_i][k])//获取最小cost(局部最小)
{
cost[index_i][k] = now;
if (now < perfect_cost_line)//从最小的cost选取更小的(全局最小)
{
perfect_cost_line = now;
pre = p;
}
}
++j;
}
++k;
}
tagList.add(pre);//记录最优标签
preTagSet = curTagSet;
}
tagList.add(tagList.get(0)); // 对于最后一个##末##
return tagList;
}
通过维特比算法就得到了最优标签:

模式匹配
接下来就是模式匹配了,就是根据给定的几种模式,在指定字符串中找出是否存在该模式。
在地名识别中,作者定义的几种模式是:
各个标签标示的含义在上面已经说过了。比如模式CH就标示:中国地名第一个字+中国地名后缀可以标示一个地名。
根据上一步得到的最优标签,即标签字符串SAAGGGGCDEHBABS,那么现在的问题就是那些模式存在该字符串中?当然是用AC自动机来解决这个问题了:多模式匹配(HanLP使用的是基于双数组的AC自动机,之前已经介绍过了)。
通过AC自动机,找出了模式CDEH存在字符串SAAGGGGCDEHBABS中,所以词(黑->C , 牛->D, 沟->E , 村->H)可以组成一个地名:黑牛沟村
那么最终的分词结果就是:
[蓝翔, 给, 宁夏, 固原市, 彭阳县, 红河镇, 黑牛沟村, 捐赠, 了, 挖掘机]
参考文献:
31 Aug 2018 |
NLP |
人名的识别是建立在初步分词的基础之上的。关于人名的详细描述(存在的问题,如何来做),请参考【基于角色标注的中国人名自动识别研究】这篇文章,里面写的很详细。
下面的内容是HanLP中的代码实现的个人解读,实现的核心思想还是根据上面的那篇文章来的,所以那篇文章应该好好看看。
HanLP人名识别
假设有一个例句:
签约仪式前,秦光荣、李纪恒、仇和等一同会见了参加签约的企业家。
我们要识别出其中的人名,应该怎么来做?
/**
* 中国人名识别
* @author hankcs
*/
public class DemoChineseNameRecognition
{
public static void main(String[] args)
{
String[] testCase = new String[]{
"签约仪式前,秦光荣、李纪恒、仇和等一同会见了参加签约的企业家。"
};
Segment segment = HanLP.newSegment().enableNameRecognize(true);//开启人名识别功能
for (String sentence : testCase)
{
List<Term> termList = segment.seg(sentence);
System.out.println(termList);
}
}
}
首先,进行初步分词,与之前介绍的方法一样(比如,可以使用简单的维特比分词)。
那么,我们得到的粗分结果如下:
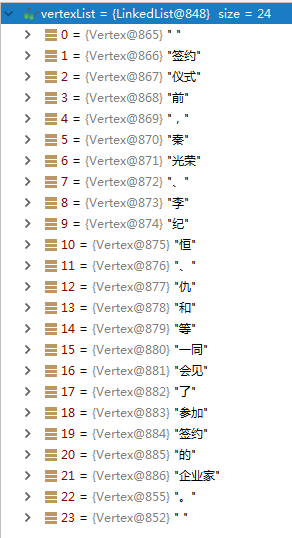
可以看到,粗分结果中,没有识别出其中的人名(秦光荣、李纪恒、仇和)。然后,使用用户自定义的词典,对粗分结果,进行调整。得到如下的结果:
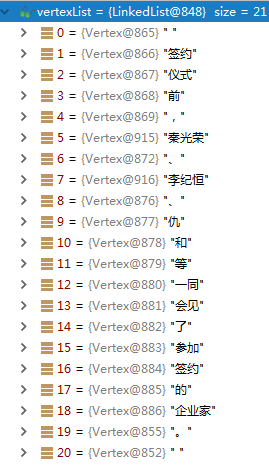
自定义的词典中如果有句子里面的人名,就可以直接匹配出来(DoubleArrayTrie加载词典,匹配字符)。但是,词典是有限的,并不能完全解决人名识别的问题,所以,上面这一步,也还没有识别出仇和这个人名,接下来,进入人名识别的具体方法。
人名识别
public static boolean recognition(List<Vertex> pWordSegResult, WordNet wordNetOptimum, WordNet wordNetAll)
{
List<EnumItem<NR>> roleTagList = roleObserve(pWordSegResult);//对粗分结果进行人名规则标记
List<NR> nrList = viterbiComputeSimply(roleTagList);//维特比找出最有可能的人名词性
PersonDictionary.parsePattern(nrList, pWordSegResult, wordNetOptimum, wordNetAll);//按照预定义的模式匹配标注的词性
return true;
}
上面主要分为了三个步骤,进行人名识别。在进入具体的实现时,先简要说一下,这里使用的人名规则。更具体的,请参考上面的论文。
一些字符表示的意义,即人名标签
/**
* 人名标签
* @author hankcs
*/
public enum NR
{
/**
* Pf 姓氏 【张】华平先生
*/
B,
/**
* Pm 双名的首字 张【华】平先生
*/
C,
/**
* Pt 双名的末字 张华【平】先生
*/
D,
/**
* Ps 单名 张【浩】说:“我是一个好人”
*/
E,
/**
* Ppf 前缀 【老】刘、【小】李
*/
F,
/**
* Plf 后缀 王【总】、刘【老】、肖【氏】、吴【妈】、叶【帅】
*/
G,
/**
* Pp 人名的上文 又【来到】于洪洋的家。
*/
K,
/**
* Pn 人名的下文 新华社记者黄文【摄】
*/
L,
/**
* Ppn 两个中国人名之间的成分 编剧邵钧林【和】稽道青说
*/
M,
/**
* Ppf 人名的上文和姓成词 这里【有关】天培的壮烈
*/
U,
/**
* Pnw 三字人名的末字和下文成词 龚学平等领导, 邓颖【超生】前
*/
V,
/**
* Pfm 姓与双名的首字成词 【王国】维、
*/
X,
/**
* Pfs 姓与单名成词 【高峰】、【汪洋】
*/
Y,
/**
* Pmt 双名本身成词 张【朝阳】
*/
Z,
/**
* Po 以上之外其他的角色
*/
A,
/**
* 句子的开头
*/
S,
}
人名词典,大概是这样的:
......
筹集 L 3
签 D 8 L 5 E 1 K 1
签单 L 2
签发 L 1
签名 L 36
签字 L 1
签完 L 4
签批 L 1
签约 L 10 K 7
......
每一行表示的意义是: 词 人名词性A A的频次 人名词性B B的频次
比如: 签约 L 10 K 7 表示词签约作为人名标签L(人名的下文)在语料中出现的次数是10次,作为人名标签K(人名的上文)在语料中出现的次数是7次。
还有一个二元词典描述的是人名标签之间的转移频次,A@A、A@B等等出现的频次。

角色观察roleObserve
角色观察所做的事情就是对粗分的结果,标注每个词的可能人名标签(用人名词典去匹配)。
/**
* 角色观察(从模型中加载所有词语对应的所有角色,允许进行一些规则补充)
* @param wordSegResult 粗分结果
* @return
*/
public static List<EnumItem<NR>> roleObserve(List<Vertex> wordSegResult)
{
List<EnumItem<NR>> tagList = new LinkedList<EnumItem<NR>>();
Iterator<Vertex> iterator = wordSegResult.iterator();
iterator.next();
tagList.add(new EnumItem<NR>(NR.A, NR.K)); // 始##始 A K
while (iterator.hasNext())
{
Vertex vertex = iterator.next();
EnumItem<NR> nrEnumItem = PersonDictionary.dictionary.get(vertex.realWord);//在人名词典中获取词的标签
if (nrEnumItem == null)//如果在词典中,不存在该词,做一些默认处理
{
//自己定义,默认处理....
}
tagList.add(nrEnumItem);//添加人名标签
}
return tagList;
}
角色观察得到的结果是:
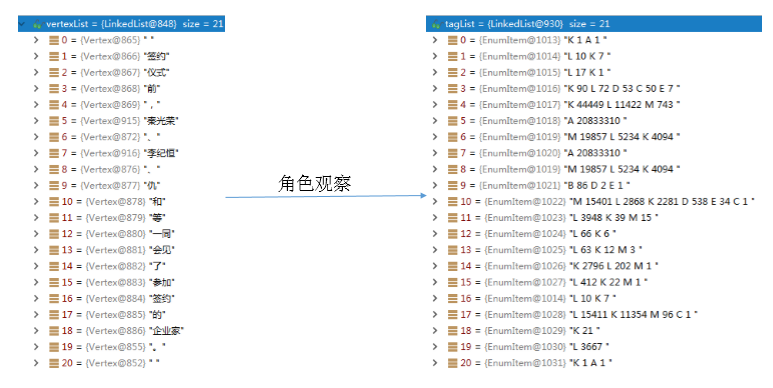
上面的左右图对照着看,就知道了每个词对应的可能人名标签。接着,就需要找出,这些标签中,每个词最有可能的标签是哪一个。
维特比
HanLP源码中使用了维特比算法(维特比算法在之前已经介绍过了)找最短路径,即找出每个词最有可能的人名标签,上面得到的结果中,一个词可能有多个人名标签。这一步得到的结果是:

模式解析
维特比解码之后,得到了每个词的人名标签词串KLLKKAKAKBELLLKLLLKLA,那么现在要做的事情就是根据自定义的模式在人名标签词串中找出存在的模式。
/**
* 人名识别模式串
*
* @author hankcs
*/
public enum NRPattern
{
BBCD,
BBE,
BBZ,
BCD,
BEE,
BE,
BC,
BEC,
BG,
DG,
EG,
BZ,
EE,
FE,
FC,
FB,
FG,
Y,
XD
}
人名识别模式串是自己定义的,认为按照这样的规则组合才能算是人名。比如BBCD 表示:姓氏 姓氏 双名的首字 双名的末字,这种规则可以认为是一种人名,其他模式是类似的。
现在的问题就是,存在一个字符串KLLKKAKAKBELLLKLLLKLA,有多个模式,如何在字符串中找出存在的模式呢?当然是用AC自动机了,来实现多模式匹配(HanLP使用的是基于双数组的AC自动机,之前已经介绍过了)。
那么,最终找出了模式BE在字符串KLLKKAKAKBELLLKLLLKLA中,所以BE对应的两个词是可以组合在一起形成一个人名的,即仇和是一个人名(B->仇,E->和 )。
那么最终的分词结果就是:
[签约, 仪式, 前, ,, 秦光荣, 、, 李纪恒, 、, 仇和, 等, 一同, 会见, 了, 参加, 签约, 的, 企业家, 。]
参考文献: