地名识别
09 Sep 2018 | NLP |地名的识别与人名的识别所用的方法是一样的,只是所用的词典与模式不同。在这篇文章中【基于层叠隐马尔可夫模型的中文命名实体识别】,也有详细的说明。
地名识别主要步骤:
- 粗分句子
- 地名词性标注
- 找出最有可能的词性
- 模式匹配
现在,我有一个句子,如何识别出其中的地名呢?
蓝翔给宁夏固原市彭阳县红河镇黑牛沟村捐赠了挖掘机。
首先,用简单的分词方法(比如:维特比分词),对句子进行初步的划分,得到如下的结果:
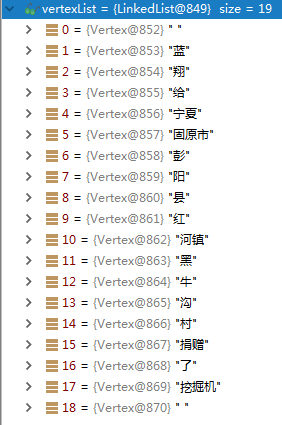
然后,使用自定义词典,对粗分结果进一步匹配,得到如下结果:
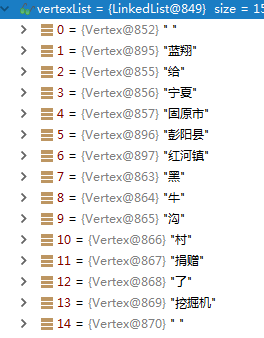
可以看到,通过自定义词典已经识别出了一些地名 彭阳县,红河镇,所以字典质量是非常重要的,但是字典又无法收录全部的地名,那么我们还是需要一些具体的方法去识别地名。
地名词性标注
地名词性标注是在对句子分词的基础之上进行的,对每个词进行地名词性的标注,这个过程是如何完成的呢?当然还是大家所熟悉的方法–通过地名词典匹配。地名词典大概是这样的:
......
日 A 146 C 46 B 27 D 14 X 1
日方 A 3
日晒 B 1
日本 G 10805
日本国 A 7
日渐 B 4
日照 G 58
日益 B 28
日程 B 1
日耳曼 G 27
......
这个词典的格式是:词 词性1 词性1的频次 词性2 词性2的频次
它这里用的标签是自己定义的:
/**
* 地名角色标签
*
* @author hankcs
*/
public enum NS
{
/**
* 地名的上文 我【来到】中关园
*/
A,
/**
* 地名的下文刘家村/和/下岸村/相邻
*/
B,
/**
* 中国地名的第一个字
*/
C,
/**
* 中国地名的第二个字
*/
D,
/**
* 中国地名的第三个字
*/
E,
/**
* 其他整个的地名
*/
G,
/**
* 中国地名的后缀海淀/区
*/
H,
/**
* 连接词刘家村/和/下岸村/相邻
*/
X,
/**
* 其它非地名成分
*/
Z,
/**
* 句子的开头
*/
S,
}
那么词典中的 日本 G 10805 这个就表示词日本作为地名词性G( 其他整个的地名)在整个语料中出现的次数是10805词。
通过上面的词典和角色标签,我们得到了地名词性标注如下:

找出最有可能的词性
通过上面的步骤得到的每个词的词性,但是我们需要找出最有可能的词性,这如何做到呢?作者使用了维特比算法解决了这个问题。维特比的核心思想是:局部最优达到全局最优。
/**
* 标准版的Viterbi算法,查准率高,效率稍低
*
* @param roleTagList 观测序列
* @param transformMatrixDictionary 转移矩阵
* @param <E> EnumItem的具体类型
* @return 预测结果
*/
public static <E extends Enum<E>> List<E> computeEnum(List<EnumItem<E>> roleTagList, TransformMatrixDictionary<E> transformMatrixDictionary)
{
int length = roleTagList.size() - 1;
List<E> tagList = new ArrayList<E>(roleTagList.size());//存放最优标签
double[][] cost = new double[2][]; // 滚动数组
Iterator<EnumItem<E>> iterator = roleTagList.iterator();
EnumItem<E> start = iterator.next();
E pre = start.labelMap.entrySet().iterator().next().getKey();
// 第一个是确定的
tagList.add(pre);
// 第二个也可以简单地算出来
Set<E> preTagSet;
{
EnumItem<E> item = iterator.next();
cost[0] = new double[item.labelMap.size()];
int j = 0;
for (E cur : item.labelMap.keySet())
{
cost[0][j] = transformMatrixDictionary.transititon_probability[pre.ordinal()][cur.ordinal()] - Math.log((item.getFrequency(cur) + 1e-8) / transformMatrixDictionary.getTotalFrequency(cur));
++j;//计算每次转移的代价cost(取频率的负对数,所以cost越小越好)
}
preTagSet = item.labelMap.keySet();
}
// 第三个开始复杂一些
for (int i = 1; i < length; ++i)
{
int index_i = i & 1;//用于滚动数组
int index_i_1 = 1 - index_i;//用于滚动数组
EnumItem<E> item = iterator.next();
cost[index_i] = new double[item.labelMap.size()];
double perfect_cost_line = Double.MAX_VALUE;
int k = 0;
Set<E> curTagSet = item.labelMap.keySet();
for (E cur : curTagSet)
{
cost[index_i][k] = Double.MAX_VALUE;
int j = 0;
for (E p : preTagSet)
{
double now = cost[index_i_1][j] + transformMatrixDictionary.transititon_probability[p.ordinal()][cur.ordinal()] - Math.log((item.getFrequency(cur) + 1e-8) / transformMatrixDictionary.getTotalFrequency(cur));//计算每次转移的代价cost(取频率的负对数,所以cost越小越好)
if (now < cost[index_i][k])//获取最小cost(局部最小)
{
cost[index_i][k] = now;
if (now < perfect_cost_line)//从最小的cost选取更小的(全局最小)
{
perfect_cost_line = now;
pre = p;
}
}
++j;
}
++k;
}
tagList.add(pre);//记录最优标签
preTagSet = curTagSet;
}
tagList.add(tagList.get(0)); // 对于最后一个##末##
return tagList;
}
通过维特比算法就得到了最优标签:

模式匹配
接下来就是模式匹配了,就是根据给定的几种模式,在指定字符串中找出是否存在该模式。
在地名识别中,作者定义的几种模式是:
CH
CDH
CDEH
GH
各个标签标示的含义在上面已经说过了。比如模式CH就标示:中国地名第一个字+中国地名后缀可以标示一个地名。
根据上一步得到的最优标签,即标签字符串SAAGGGGCDEHBABS,那么现在的问题就是那些模式存在该字符串中?当然是用AC自动机来解决这个问题了:多模式匹配(HanLP使用的是基于双数组的AC自动机,之前已经介绍过了)。
通过AC自动机,找出了模式CDEH存在字符串SAAGGGGCDEHBABS中,所以词(黑->C , 牛->D, 沟->E , 村->H)可以组成一个地名:黑牛沟村
那么最终的分词结果就是:
[蓝翔, 给, 宁夏, 固原市, 彭阳县, 红河镇, 黑牛沟村, 捐赠, 了, 挖掘机]
参考文献:
- 俞鸿魁,张华平,刘群,吕学强,施水才.基于层叠隐马尔可夫模型的中文命名实体识别[J].通信学报,2006(02):87-94.
- 实战HMM-Viterbi角色标注地名识别
- HanLP地名识别Demo