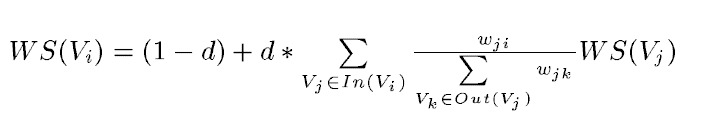基于互信息和左右信息熵的短语提取识别
04 Oct 2018 | NLP |短语提取是从一篇文章中提取出主要的短语(短语是由几个词构成的),短语提取常用于搜索引擎与推荐系统。
下面的介绍是基于HanLP的基于互信息和左右信息熵的短语提取识别开源实现。
给定文本:
"算法工程师\n" +
"算法(Algorithm)是一系列解决问题的清晰指令,也就是说,能够对一定规范的输入,在有限时间内获得所要求的输出。" +
"如果一个算法有缺陷,或不适合于某个问题,执行这个算法将不会解决这个问题。不同的算法可能用不同的时间、" +
"空间或效率来完成同样的任务。一个算法的优劣可以用空间复杂度与时间复杂度来衡量。算法工程师就是利用算法处理事物的人。\n" +
"\n" +
"1职位简介\n" +
"算法工程师是一个非常高端的职位;\n" +
"专业要求:计算机、电子、通信、数学等相关专业;\n" +
"学历要求:本科及其以上的学历,大多数是硕士学历及其以上;\n" +
"语言要求:英语要求是熟练,基本上能阅读国外专业书刊;\n" +
"必须掌握计算机相关知识,熟练使用仿真工具MATLAB等,必须会一门编程语言。\n" +
"\n" +
"2研究方向\n" +
"视频算法工程师、图像处理算法工程师、音频算法工程师 通信基带算法工程师\n" +
"\n" +
"3目前国内外状况\n" +
"目前国内从事算法研究的工程师不少,但是高级算法工程师却很少,是一个非常紧缺的专业工程师。" +
"算法工程师根据研究领域来分主要有音频/视频算法处理、图像技术方面的二维信息算法处理和通信物理层、" +
"雷达信号处理、生物医学信号处理等领域的一维信息算法处理。\n" +
"在计算机音视频和图形图像技术等二维信息算法处理方面目前比较先进的视频处理算法:机器视觉成为此类算法研究的核心;" +
"另外还有2D转3D算法(2D-to-3D conversion),去隔行算法(de-interlacing),运动估计运动补偿算法" +
"(Motion estimation/Motion Compensation),去噪算法(Noise Reduction),缩放算法(scaling)," +
"锐化处理算法(Sharpness),超分辨率算法(Super Resolution),手势识别(gesture recognition),人脸识别(face recognition)。\n" +
"在通信物理层等一维信息领域目前常用的算法:无线领域的RRM、RTT,传送领域的调制解调、信道均衡、信号检测、网络优化、信号分解等。\n" +
"另外数据挖掘、互联网搜索算法也成为当今的热门方向。\n" +
"算法工程师逐渐往人工智能方向发展。";
尝试从文本中提取出短语。
分句,分词,去掉停用词
首先,需要对整个文本进行分句,然后分词,然后去掉停用词(处理方法在之前的文章中都有介绍过了)。得到结果如下:
sentenceList = {LinkedList@906} size = 50
0 = {ArrayList@909} size = 2
0 = {Term@960} "算法/n"
1 = {Term@961} "工程师/nnt"
1 = {ArrayList@910} size = 4
0 = {Term@965} "算法/n"
1 = {Term@966} "解决问题/v"
2 = {Term@967} "清晰/a"
3 = {Term@968} "指令/n"
2 = {ArrayList@911} size = 1
0 = {Term@974} "也就是说/l"
3 = {ArrayList@912} size = 3
0 = {Term@977} "能够/v"
1 = {Term@978} "规范/v"
2 = {Term@979} "输入/v"
4 = {ArrayList@913} size = 5
0 = {Term@984} "有限/a"
1 = {Term@985} "时间/n"
2 = {Term@986} "获得/v"
3 = {Term@987} "要求/n"
4 = {Term@988} "输出/vn"
5 = {ArrayList@914} size = 2
0 = {Term@995} "算法/n"
1 = {Term@996} "缺陷/n"
6 = {ArrayList@915} size = 2
0 = {Term@1003} "适合于/v"
1 = {Term@1004} "问题/n"
7 = {ArrayList@916} size = 5
0 = {Term@1008} "执行/v"
1 = {Term@1009} "算法/n"
2 = {Term@1010} "不会/v"
3 = {Term@1011} "解决/v"
4 = {Term@1012} "问题/n"
......
(太长了,后面我省略了一些)
统计词频
得到所有的词语后,就进行词频统计,在这一步需要统计单个词频、二阶共现词频、三阶共现词频。
单个词频
单个词频就是每个词出现的总次数。比如算法 31表示词算法在整个文档中出现的次数是31次。
二阶共现词频
二阶共现词频是两个词语一起出现的次数。比如算法→工程师 10表示词算法→工程师在整个文档中出现的次数是10次。
三阶共现词频
三阶共现词频也就是二阶短语“算法→研究”后面的接续:“算法→研究→工程师”。同时,为了接下来计算的方便,还需要统计二阶串“算法→研究”的前面可能的接续“从事→算法→研究”;在源码中,作者使用了前缀树来储存词与词频,所以为了方便,记作“算法→研究←从事”。
比如算法→研究→工程师 1表示词算法→研究→工程师出现的次数是1次;
算法→研究←从事 1表示词算法→研究→从事出现的次数是1次。
为了理解前缀树,我画了一个图:
上面的图表示的是使用前缀树存储二阶共现词频(只画出了其中的一部分)。 存储的部分词:
不会→解决
不同→时间
不同→算法
算法→不会
算法→优劣
算法→可能
算法→处理
算法→工程师
算法→机器
算法→研究
算法→缺陷
算法→解决问题
算法→领域
信息熵
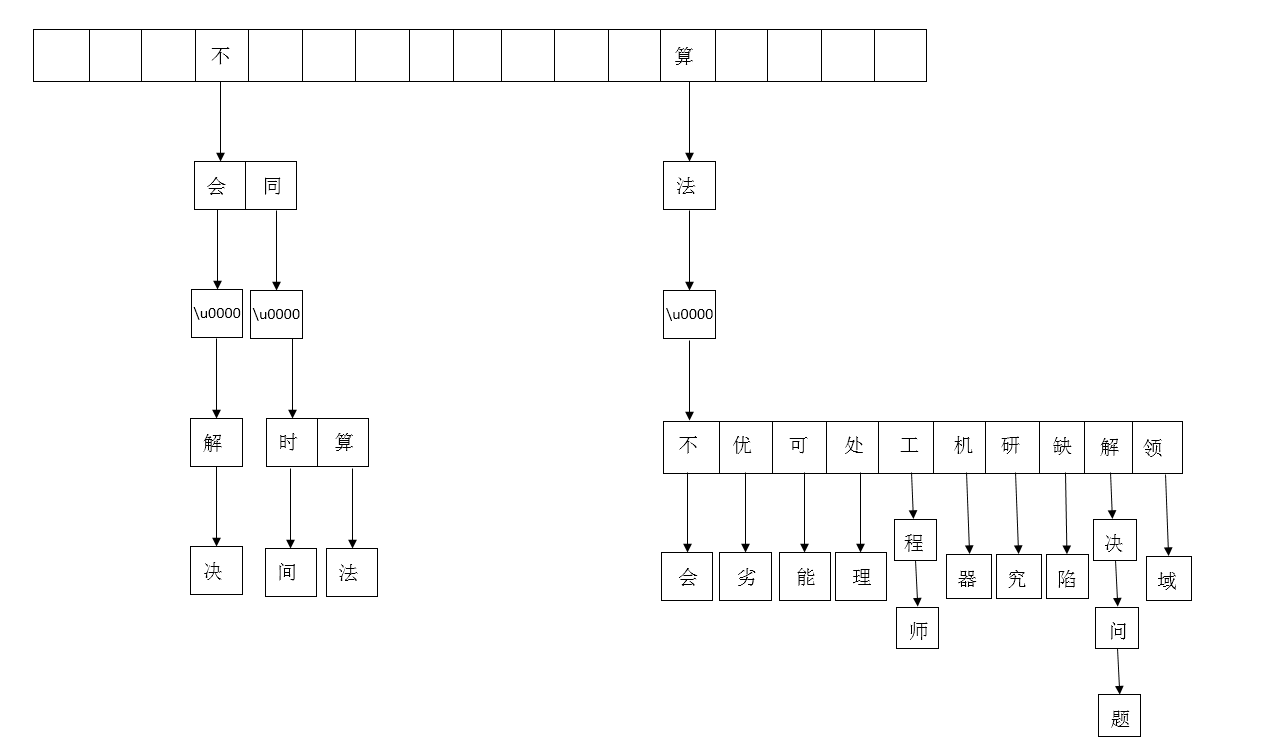
互信息体现了两个变量之间的相互依赖程度。二元互信息是指两个事件相关性的量(论文给出如下定义):
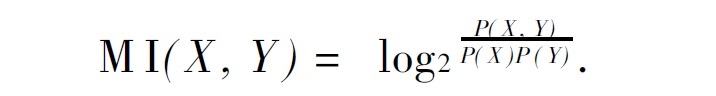
互信息值越高, 表明X和Y相关性越高, 则X和Y 组成短语的可能性越大; 反之, 互信息值越低,X 和Y之间相关性越低, 则X 和Y之间存在短语边界的可能性越大。
公式中的X和Y指的是两个相邻的单词,P值是它的出现概率。
具体到这个例子,“算法→研究”一共出现了2次,而二阶短语一共有191个,所以上式的P(X,Y)= 2 / 191。同理可以求出P(X)P(Y)。
左右熵
熵这个术语表示随机变量不确定性的量度。具体表述如下: 一般地, 设X 是取有限个值的随机变量( 或者说X 是有限个离散事件的概率场) , X 取值x 的概率为P ( x ) , 则X 的熵定义为:
左右熵是指多字词表达的左边界的熵和右边界的熵。左右熵的公式如下:
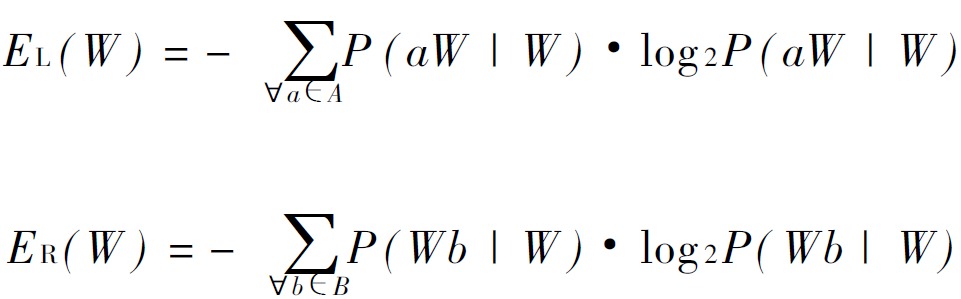
左信息熵是所有指向该词的词,比如算法→研究这个词的左信息熵相关词是:
算法→研究←从事
算法→研究←成为
右信息熵是该词指向所有的词,比如算法→研究这个词的右信息熵相关词是:
算法→研究→工程师
算法→研究→核心
最后,将每个二元共现词的互信息熵,左信息熵,右信息熵相加,得到最终的分数,取出前几个最大分数值的词,即为提取的短语。
[算法工程师, 算法处理, 一维信息, 算法研究, 信号处理]