Aho Corasick自动机结合DoubleArrayTrie分词
22 Aug 2018 | NLP |Aho-Corasick自动机算法(简称AC自动机)1975年产生于贝尔实验室。该算法应用有限自动机巧妙地将字符比较转化为了状态转移。此算法有两个特点,一个是扫描文本时完全不需要回溯,另一个是时间复杂度为O(n),时间复杂度与关键字的数目和长度无关。
DoubleArrayTrie即双数组Trie树在之前的文章中已经介绍过了。
AC自动机结合DoubleArrayTrie可以使得时间和空间利用达到最优。单纯使用DoubleArrayTrie在构建分词时,匹配失败了,会回溯;而AC自动机与DAT树的结合在匹配时一直向前,永不回退,速度会更快一些。
AC自动机的构建需要3样东西:
状态跳转表goto :决定对于当前状态S和条件C,如何得到下一状态S‘
失配跳转表fail : 决定goto表得到的下一状态无效时,应该回退到哪一个状态
匹配结果输出表output : 决定在哪个状态时输出哪个恰好匹配的模式
DAT的构建需要两样东西:
base数组:状态转移
check数组:状态回溯
AC自动机与DAT树的结合主要是使用base与check来替代goto
HanLP实现了该方法,源码在这里。
作者主要分为三个步骤:
//1. 构建二分trie树
addAllKeyword(keySet);
//2. 在二分trie树的基础上构建双数组trie树
buildDoubleArrayTrie(keySet);
//3. 构建failure表并且合并output表
constructFailureStates();
假设我的词典现在是:
he
hers
his
she
1 构建二分trie树
在这一步主要是读取词典中的词(使用TreeMap读取,可以保证有序性),记录每个词的最后一个词的位置信息。下面以一个图的形式作为展示。
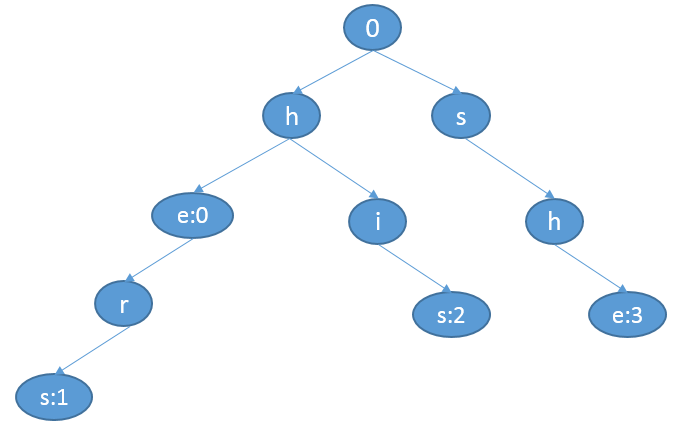
0 是根节点
e:0 表示的是词he在e结束,它在词典(TreeMap读取后保存的数据)中的第0个位置
s:1 表示的是词hers在s结束,它在词典(TreeMap读取后保存的数据)中的第1个位置
s:2 表示的是词his在s结束,它在词典(TreeMap读取后保存的数据)中的第2个位置
e:3 表示的是词she在s结束,它在词典(TreeMap读取后保存的数据)中的第3个位置
2 构建双数组trie树
构建双数组trie树的方法跟之前一样,主要构建base数组和check数组。下面以一个图的形式作为展示。
base[s] + c.code = t
check[t] = base[s]

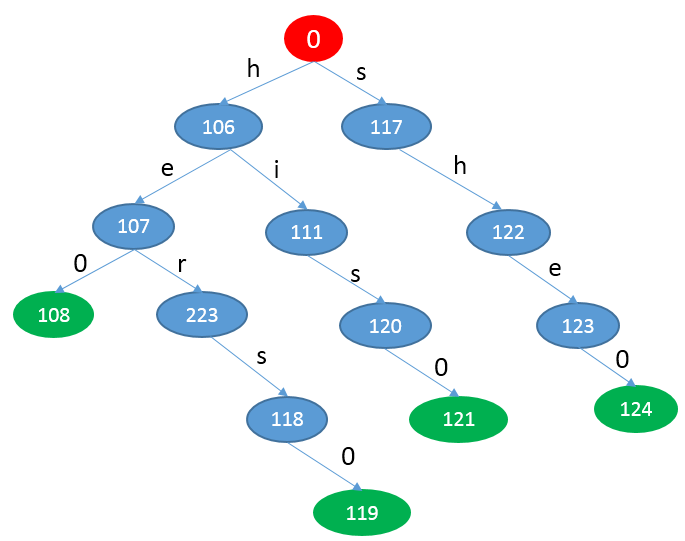
3 构建fail表与output表
fail的构建是根据上一个fail值的成功转移值得到的。
fail(s2) = goto(fail(s1),c)
s2的fail值由s1的fail根据条件c得到的成功转移值。
Note:离根节点深度为1的状态的fail值都是0,其他值就需要靠公式去计算了。
接着上面的例子,计算各个状态的fail值
fail(106)=fail(117)=0
fail(107)=goto(fail(106),e)=goto(0,e)=0
fail(223)=goto(fail(107),r)=goto(0,r)=0
fail(118)=goto(fail(223),s)=goto(0,s)=117
fail(111)=goto(fail(106),i)=goto(0,i)=0
fail(120)=goto(fail(111),s)=goto(0,s)=117
fail(122)=goto(fail(117),h)=goto(0,h)=106
fail(123)=goto(fail(122),e)=goto(106,e)=107
ouput表记录的是在成功或失败转移过程中每个完整的词。
107:0
118:1
120:2
123:3,0
123:3,0表示的是在状态123时有词典(TreeMap读取后保存的数据)中的第0个和第3个词(即he和she)。
由上面的三个过程我们就得到了最为关键的4个信息base,check,fail,output。
现在假设有一个字符串ushers,如何分词呢?
下面是HanLP中的部分源码:
/*
text:[u,s,h,e,r,s]
*/
public void parseText(char[] text, IHit<V> processor)
{
int position = 1;
int currentState = 0;
for (char c : text)
{
currentState = getState(currentState, c);//获取状态转移节点,成功转移或者失败转移
int[] hitArray = output[currentState];//该状态是否存在完整的词
if (hitArray != null)
{
for (int hit : hitArray)
{
processor.hit(position - l[hit], position, v[hit]);//记录分割位置,begin,end
}
}
++position;//一直向前,从不回退
}
}
/*******************记录开始词位置***************************/
@Override
public void hit(int begin, int end)
{
int length = end - begin;
if (length > wordNet[begin])//更新,因为找到了更长的词(这种分词方式是取最长分词)
{
wordNet[begin] = length;//记录每个词的开始位置
}
}
/*******************分词***************************/
for (int i = 0; i < wordNet.length; )//根据wordNet记录的各个词的开始位置,在原句中分词
{
Term term = new Term(new String(sentence, i, wordNet[i]));
term.offset = i;
termList.add(term);
i += wordNet[i];
}
最后的分词结果就是:[u, she, r, s ]