双数组Trie树(DoubleArrayTrie)
08 Aug 2018 | NLP |双数组Trie (Double-Array Trie)结构由日本人JUN-ICHI AOE于1989年提出的,是Trie结构的压缩形式,仅用两个线性数组来表示Trie树,该结构有效结合了数字搜索树(Digital Search Tree)检索时间高效的特点和链式表示的Trie空间结构紧凑的特点。双数组Trie的本质是一个确定有限状态自动机(DFA),每个节点代表自动机的一个状态,根据变量不同,进行状态转移,当到达结束状态或无法转移时,完成一次查询操作。在双数组所有键中包含的字符之间的联系都是通过简单的数学加法运算表示,不仅提高了检索速度,而且省去了链式结构中使用的大量指针,节省了存储空间。 ——《基于双数组Trie树算法的字典改进和实现》
双数组Trie主要用于分词中加载词典。
Double-Array Tire的本质是一颗树形结构,但是具体实现却是通过两个数组来实现的。Tire树中几个重要的概念
- STATE:状态,实际为在数组中的下标
- CODE : 状态转移值,实际为转移字符的 ASCII码
- BASE :表示后继节点的基地址的数组,叶子节点没有后继,标识为字符序列的结尾标志
- CHECK:标识前驱节点的地址
静态构造Tire树,一般双数组的实现都会对算法做一个改进,下面的算法讲解主要参考开源实现dart-clone,dart-clone 也对双数组算法做了一个改进,即
base[s] + c = t
check[t] = base[s]
Double-Array Tire的构造过程
1 建立根节点root,令base[root] = 1
2 找出root的子节点 集{root.childreni }(i = 1...n) , 使得 check[root.childreni ] = base[root] = 1
3 对 each element in root.children :
1)找到{elemenet.childreni }(i = 1...n) ,然后选择一个值begin,使得每一个check[ begini + element.childreni .code] = 0
2)设置base[element.childreni] = begini
3)对element.childreni 递归执行步骤3,若遍历到某个element,其没有children,即叶节点,则设置base[element]为负值(一般为在字典中的index取负)
示例:
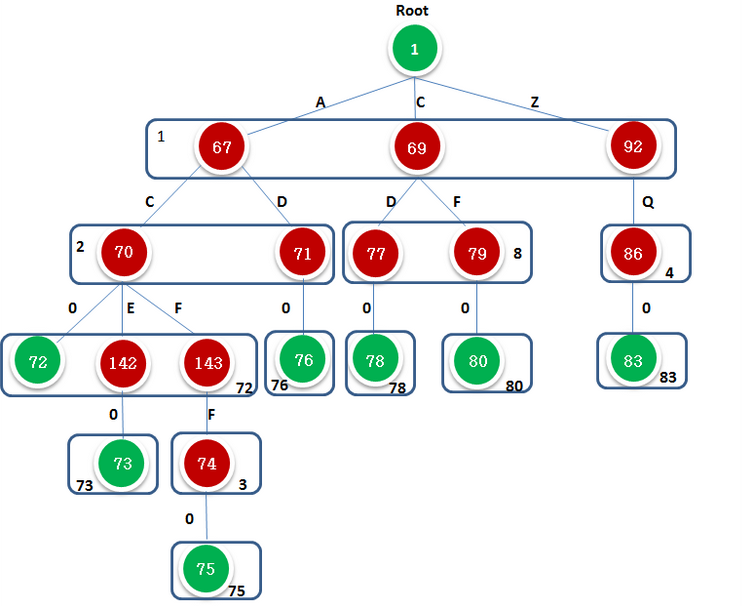
对于由Dic = { AC,ACE,ACFF,AD,CD,CF,ZQ } (在ASCII表中code有:A-65,C-67,D-68,E-69,F-70,Q-81,Z-90;在实际使用时code+1)构成的Tire树,其双数组最终生成的结果

其中i是下标,即为state,这里根据下标i可以看出BASE与CHECK数组的长度均达到了144,图中只显示了BASE与CHECK中不为0的信息。
展开成树的形式就是这样的:
一步步构建Trie:
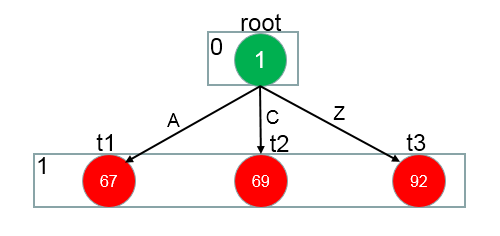
1 root –> A , C , Z
遍历字典,找到root的所有children,在Dic中为{A , C, Z}, root经过A , C, Z 的作用分别到达三个状态 t1 ,t2 , t3
base[root] + A.code = t1
check[t1] = base[root]
base[root] + C.code = t2
check[t2] = base[root]
base[root] + Z.code = t3
check[t3] = base[root]
那么我们如何寻找begin的值呢?使得check[ begini + element.childreni .code] = 0成立。
下面是一个求解过程的伪代码,具体的代码实现可以参考 HanLP中的DoubleArrayTrie
begin = 0
pos = max(A.code + 1, nextCheckPos) - 1 # nextCheckPos(初始值为0)每次与根节点的第一个孩子节点比较,此时pos=66
while(true){
pos++
if(check[pos] != 0){#找到check[pos]=0的值
continue
}
nextCheckPos = pos #此时nextCheckPos = pos = 67
begin = pos - A.code #此时begin = 1
if(used.get(begin)){#检查begin是否被占用
continue
}
break
}
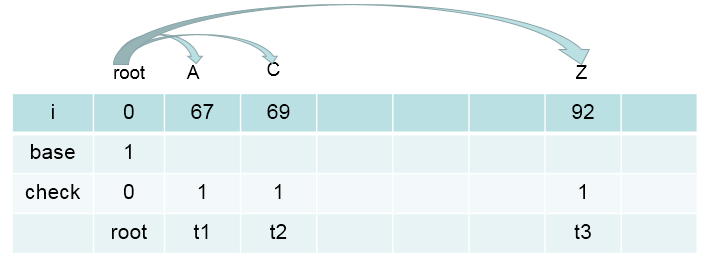
# 通过上述过程就找到了合适的begin的值,此时 begin = 1, 根据步骤3.1,3.2,可得base[root] = 1
那么两个数组的转态转移值为:
base[root] + A.code = 1 + 66 = 67 = t1
check[t1] = 1
base[root] + C.code = 1 + 68 = 69 = t2
check[t2] = 1
base[root] + Z.code = 1 + 91 = 92 = t3
check[t3] = 1
此时数双组的值为:
树形结构为:
2 A –>C , D
接着递归A节点,A的子节点有{C,D}, A经过C , D 的作用分别到达三个状态 t4 , t5
base[A] + C.code = t4
check[t4] = base[A]
base[A] + D.code = t5
check[t5] = base[A]
求解begin的过程:
begin = 0
# nextCheckPos每次与根节点的第一个孩子节点比较,上次nextCheckPos=67
# 所以此时 pos = max(68+1,67)-1 = 68
pos = max(C.code + 1, nextCheckPos) - 1
while(true){
pos++
if(check[pos] != 0){ #对照着看上一次的表格,就知道check[pos]的值是否为0,即是否被占用
continue
}
nextCheckPos = pos #此时nextCheckPos = pos = 70
begin = pos - C.code #此时begin = 70-68 = 2
if(used.get(begin)){#检查begin是否被占用
continue
}
break
}
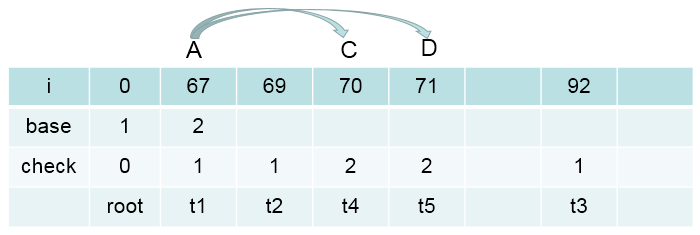
# 通过上述过程就找到了合适的begin的值,此时 begin = 2,
# 根据步骤3.1,3.2,可得base[A] = base[t1] = begin = 2
那么两个数组的转态转移值为:
base[A] + C.code = 2 + 68 = 70 = t4
check[t4] = 2
base[A] + D.code = 2 + 69 = 71 = t5
check[t5] = 2
此时数双组的值为:
树形结构为:
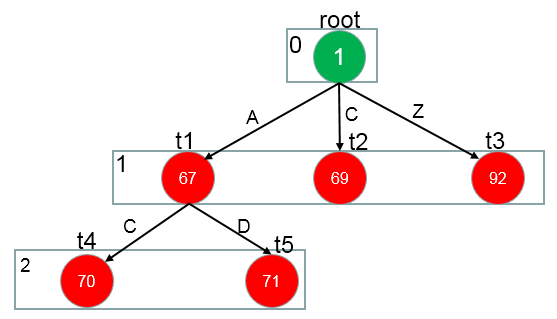
3 C –>0 , E, F
接着递归A节点,A的子节点有{0,E,F}, A经过0 ,E , F 的作用分别到达三个状态 t6 , t7, t8
base[C] + 0.code = t6
check[t6] = base[C]
base[C] + E.code = t7
check[t7] = base[C]
base[C] + F.code = t8
check[t8] = base[C]
求解begin的过程:
begin = 0
# nextCheckPos每次与根节点的第一个孩子节点比较,上次nextCheckPos=70
# 所以此时 pos = max(0+1,70)-1 = 69
pos = max(0.code + 1, nextCheckPos) - 1
while(true){
pos++
if(check[pos] != 0){ #对照着看上一次的表格,就知道check[pos]的值是否为0,即是否被占用
continue
}
nextCheckPos = pos #此时nextCheckPos = pos = 72
begin = pos - 0.code #此时begin = 72 - 0 =72
if(used.get(begin)){#检查begin是否被占用
continue
}
break
}
# 通过上述过程就找到了合适的begin的值,此时 begin = 72,
# 根据步骤3.1,3.2,可得base[C] = base[t4] = begin = 72
那么两个数组的转态转移值为:
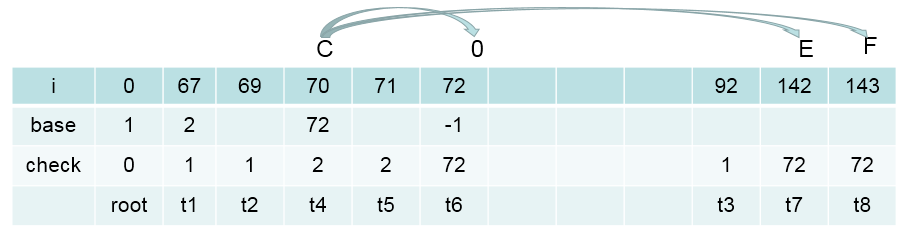
base[C] + 0.code = 72 + 0 = 72 = t6
check[t6] = 72
base[C] + E.code = 72 + 70 = 142 =t7
check[t7] = 72
base[C] + F.code = 72 + 71 = 143 = t8
check[t8] = 72
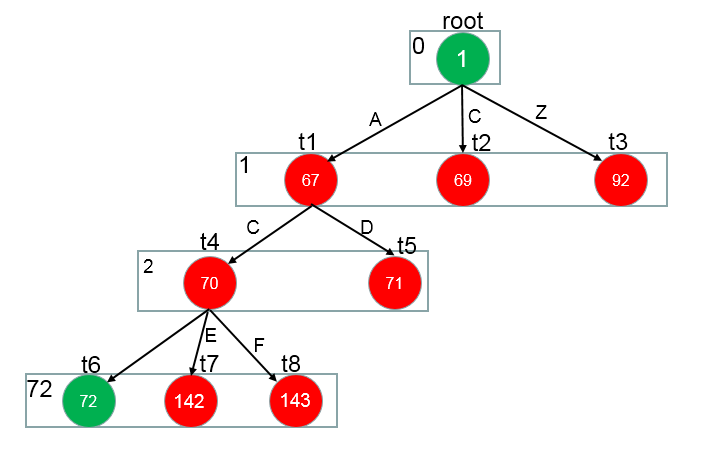
此时,节点中有叶子节点,那么它(‘0’)就遍历结束了(叶子节点直接处理:base[72] = -1(-1是字符串在字典中的索引值), check[72] = 72),接着处理它(‘0’)的兄弟节点E
此时数双组的值为:
树形结构为:
4 E –>0
接着递归E节点,E的子节点只有{0}, E经过0 的作用到达状态 t9
base[E] + 0.code = t9
check[t9] = base[E]
求解begin的过程:
begin = 0
# nextCheckPos每次与根节点的第一个孩子节点比较,上次nextCheckPos=72
# 所以此时 pos = max(0+1,72)-1 = 71
pos = max(0.code + 1, nextCheckPos) - 1
while(true){
pos++
if(check[pos] != 0){ #对照着看上一次的表格,就知道check[pos]的值是否为0,即是否被占用
continue
}
nextCheckPos = pos #此时nextCheckPos = pos = 73
begin = pos - 0.code #此时begin = 73 - 0 =73
if(used.get(begin)){#检查begin是否被占用
continue
}
break
}
# 通过上述过程就找到了合适的begin的值,此时 begin = 73,
# 根据步骤3.1,3.2,可得base[E] = base[t7] = begin = 73
那么两个数组的转态转移值为:
base[E] + 0.code = 73 + 0 = 73 = t9
check[t9] = 73
此时,节点中有叶子节点,那么它(‘0’)就遍历结束了(叶子节点直接处理:base[73]=base[t9] = -2(-2是字符串在字典中的索引值), check[73] = 73),接着处理它(‘0’)的兄弟节点F
此时数双组的值为:
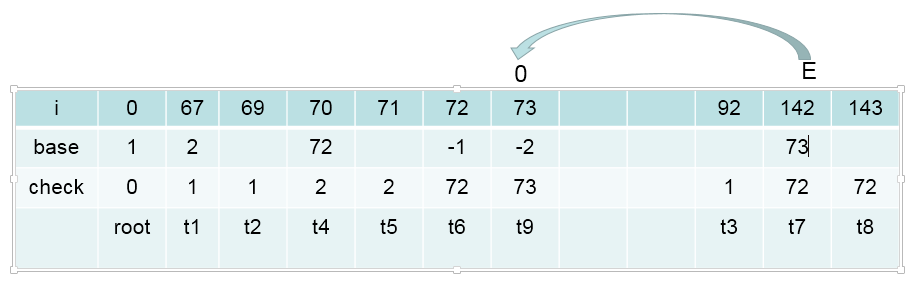
树形结构为:
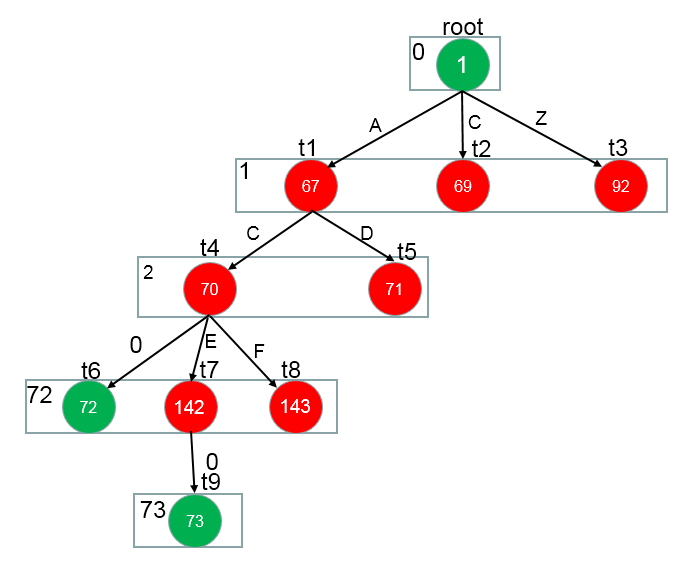
5 F –>F
接着递归F节点,F的子节点只有{F}, F经过F 的作用到达状态 t10
(…… 省略剩下的过程了,方法是一样的)
按照上面一样的方法进行计算,我们就可以得到最终的构造,生成DoubleArray-Trie
此时数双组的值为:

树形结构为:
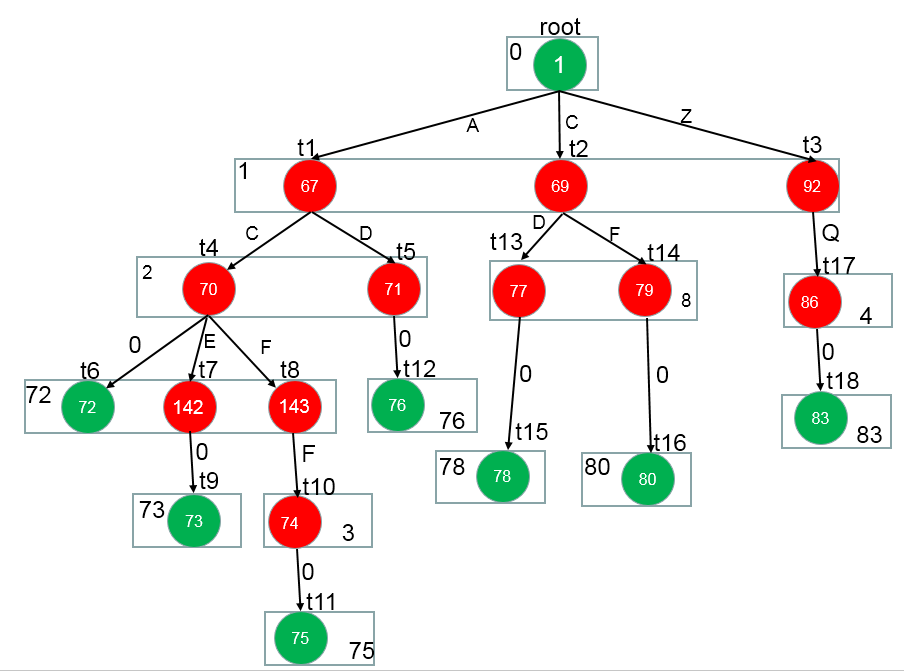
Note: nextCheckPos是DoubleArray-Trie的一个字段,不是递归时的局部变量。
Tire树的查询
有了如上的构建过程,查询就很简单了:
根据转移方程:
base[s] + c = t
check[t] = base[s]
当有 check[t] == t 时,说明遇到了叶子节点,那么有base[t]=index,记录下其位置index,然后输出Dic[index]即为匹配出来的dic中的词。