13 Jan 2019 |
deep-learning |
1.为什么需要激活函数?
没有激活函数相当于矩阵相乘,多层和一层一样,只能拟合线性函数
2.万有逼近定理
如果一个隐层包含足够多的神经元,三层前馈神经网络(输入-隐层
-输出)能以任意精度逼近任意预定的连续函数。
3.双隐层感知器逼近非连续函数
当隐层足够宽时,双隐层感知器(输入-隐层1-隐层2-输出)可以逼
近任意非连续函数:可以解决任何复杂的分类问题。
4.神经网络每一层的作用
- 每一层的数学公式:
y=a(wx+b),完成输入到输出的空间变换
wx:升维/降维、放大/缩小、旋转b:平移a(.):弯曲
神经网络学习如何利用矩阵的线性变换加激活函数的非线性变换,
将原始输入空间投影到线性可分的空间去分类/回归。
增加节点数:增加维度,即增加线性转换能力。
增加层数:增加激活函数的次数,即增加非线性转换次数
5.网络更深or更宽?
在神经元总数相当的情况下,增加网络深度可以比增加宽度带来
更强的网络表示能力:产生更多的线性区域
6.机器学习中的数学基础
- 线性代数:数据表示、空间变换的基础
- 概率论:模型假设、策略设计的基础
- 最优化:求解目标函数的具体算法
7.矩阵特征向量
矩阵变换时,只有尺度变换而没有方向变换的向量就是它的特征向量
8.矩阵的秩
线性方程组的角度:度量矩阵行列之间的相关性
- 如果矩阵的各行或列是线性无关的,矩阵就是满秩的,也就是秩等于行数
数据点分布的角度:表示数据需要的最小的基的数量
- 数据分布模式越容易被捕捉,即需要的基越少,秩就越小
- 数据冗余度越大,需要的基就越少,秩越小
- 若矩阵表达的是结构化信息,如图像、用户-物品表等,各行之间存在一定相关性,一般是低秩的
9.欠拟合 vs 过拟合
- 欠拟合:训练集的一般性质尚未被学习器学好. (在训练集上误差都还很大)
欠拟合解决办法:增加网络层数、每层节点数、训练周期
- 过拟合:学习器把训练集特点当做样本的一般特点. (在训练集上误差很小了,但是在测试集上误差还是很大)
过拟合解决办法:dropout、early stop、regularization
10.频率学派 vs 贝叶斯学派
- 频率学派:参数估计只依赖观测数据;设计不同概率模型去拟合数据背后的规律,用拟合出的规律去推断和预测未知的结果
- 贝叶斯学派:参数估计同时依赖观测数据和先验知识;根据数据+变量的先验分布,同时推断每个变量以及变量之间关系的后验分布
12 Jan 2019 |
deep-learning |
人工智能
使一部机器像人一样进行感知、认知、决策、执行的人工程序或系统。
图灵测试
如果一个人(代号C)使用测试对象皆理解的语言去询问两个他不能看见的对象任意一串问题。对象为:一个是正常思维的人(代号B)、一个是机器(代号A)。如果经过若干询问以后,C不能得出实质的区别来分辨A与B的不同,则此机器A通过图灵测试。
机器学习
计算机系统能够利用经验提高自身的性能
模型分类
1 数据标记
- 监督学习:数据标记已知,目的在于学习从输入到输出之间的映射
- 无监督学习:数据标记未知,目的在于发现数据中有意义的信息
- 半监督学习:部分数据已知,监督学习和无监督学习的混合
- 强化学习:数据标记未知,但是可以为输出目标提供反馈
2 数据分布
- 参数模型:对数据分开可以做出假设,选择一个模型(该模型的参数数目是有限且固定的)来刻画它
- 非参数模型:不对数据分布进行假设,数据的所有统计特性都来源于数据本身
3 建模对象
- 生成模型:对输入X和输出Y的联合分布P(X,Y)建模(先求联合分布p(x,y),然后利用贝叶斯公式求p(y|x))
- 判别模型:对已知输入X条件下输出Y的条件分布P(Y|X)建模(直接求p(y|x))
机器学习 VS 深度学习
- 基于规则的系统: 输入 –> 手动设计规则 –> 输出
- 传统机器学习: 输入 –> 手动设计特征 –> 特征映射 –> 输出
- 深度学习: 输入 –> 手动抽取简单特征 –> 神经网络抽取更复杂的特征–> 特征映射 –> 输出
深度学习的局限
- 输出不稳定,容易被攻击;对输入稍加改变就输出错误结果
- 模型复杂度高,难以调试和纠错;不易复现
- 模型层级复合程度高,参数不透明
- 端到端训练方式对数据依赖性强,模型增量性差;不好作为一个组件逐步加到系统中
- 专注直观感知类问题,对开放性推理问题无能为力
- 人类知识无法有效引入进行监督,机器偏见难以避免
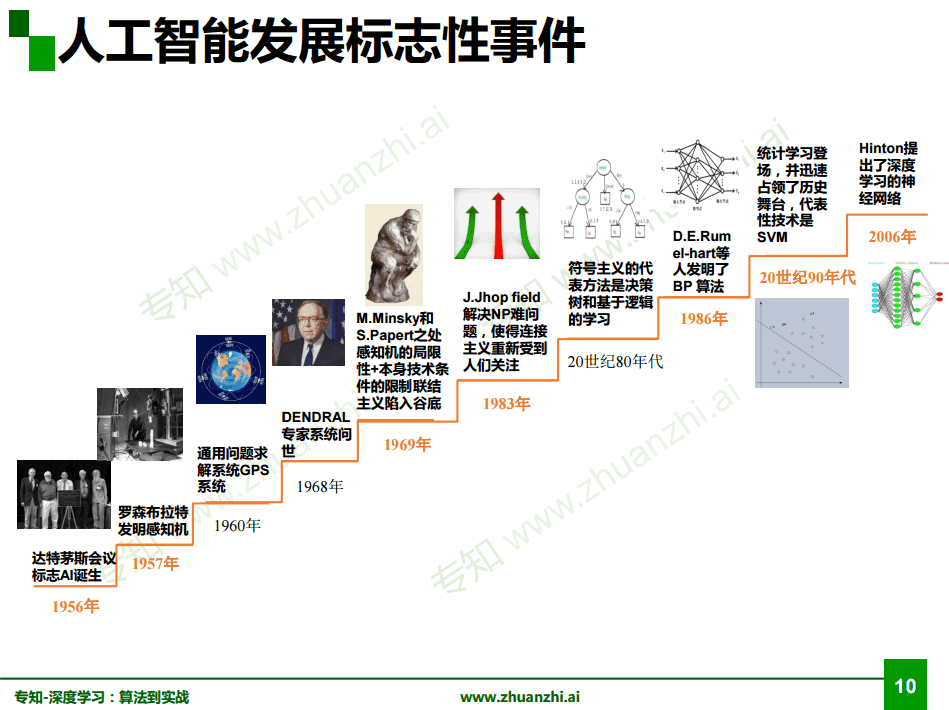
人工智能发展史:
参考资料:
深度学习:算法到实战
19 Nov 2018 |
NLP |
论文(Wang X, Han X, Lin Y, et al. Adversarial Multi-lingual Neural Relation Extraction[C]//Proceedings of the 27th International Conference on Computational Linguistics. 2018: 1156-1166.
) 使用对抗性神经网络来进行多语言的关系抽取。
论文的主要贡献:
- 使用对抗性网络来获取语言一致性信息
- 使用卷积网络来获取语言多样性信息
在表达同一种意思的时候,人们的表达形式是多种多样的,可以是声音,可以是手势,可以是图像,可以是文字。那么论文作者认为在不同语言之间也是存在语言一致性的,所以使用对抗网络来获取语言一致性信息。同时,不同语言本身是具有多样性的,所以还需考虑语言的多样性信息。
输入
语料是由汉语与英语构成的。一个示例由一个三元组,多个英语句子,多个汉语句子构成,这些句子共用同一个三元组。
Note:实体是可以用id来表示的,比如汉语“比利时”和英语“Belgium”对应同一个id:Q31
Instance:
(entity1, rel, entity2)
en:
sen_en1
sen_en2
sen_en3
zh:
sen_zh1
sen_zh2
网络架构
网络整体的架构包括单语关系抽取与多语关系抽取。
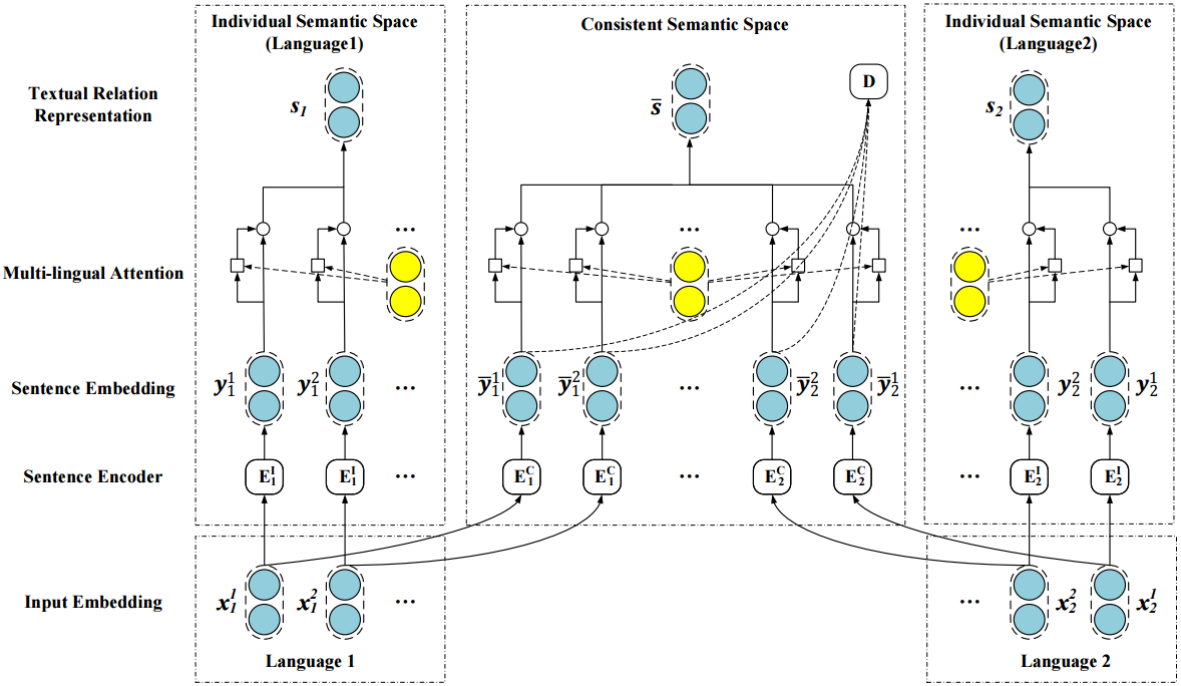
为了更加直观的理解模型,我画了一个参数模型。
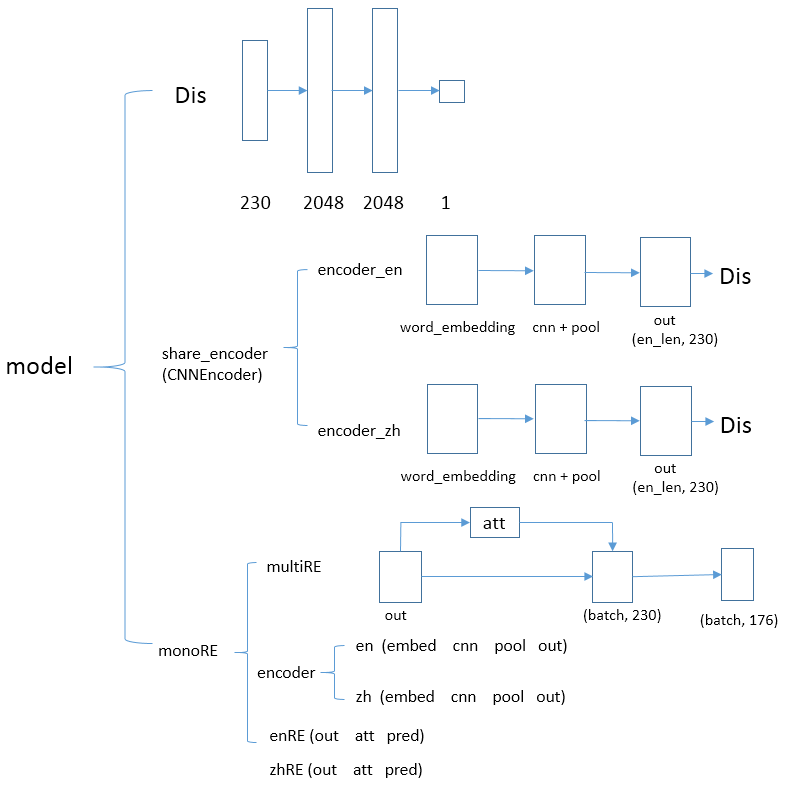
- 第一部分是判别器:判别器由多个线性层组成,用于区分语言(0代表英语,1代表汉语)
- 第二部分是卷积编码器:卷积编码器是为了抽取语言特征,将意义相同多种语言映射到同一个空间;它主要由词嵌入、卷积、池化操作构成
- 关系抽取:进行单语与多语的关系抽取
对抗网络
判别器:将语言进行卷积编码,然后输入到判别器,判别器的输出是0或者1,用于区分是哪一种语言;
欺骗器:将语言进行卷积编码,然后输入到判别器,让判别器的输出是1或者0,尽量不让判别器做出正确的区分。
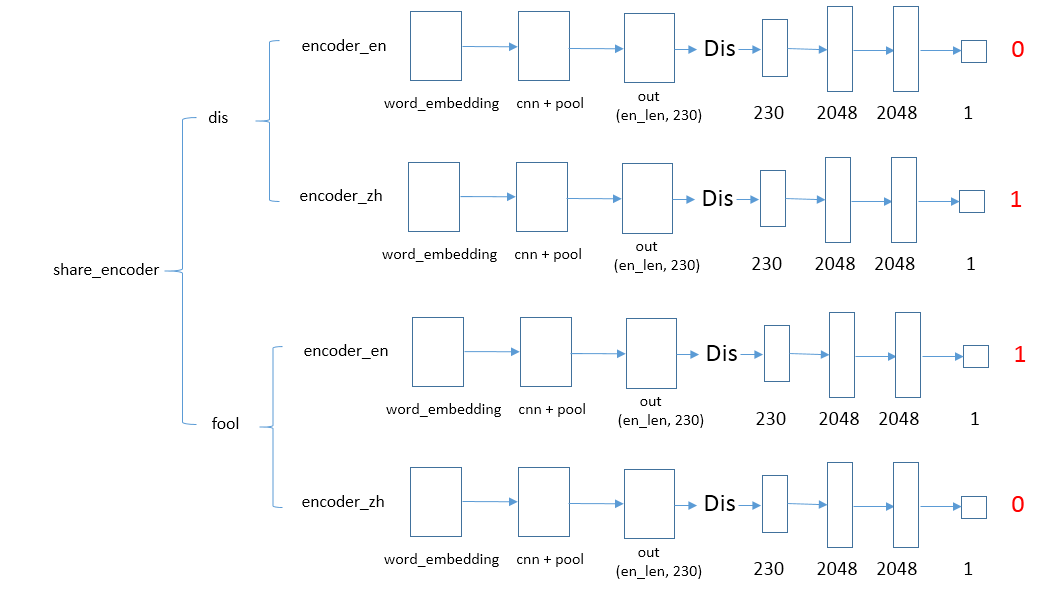
经上面反复的训练,对抗网络最终达到一个平衡的状态,无法区分出是哪一种语言了,效果就是:表达意义一样的多语句子映射到同一个空间的时候会很接近,不同意义的句子就会离的很远。
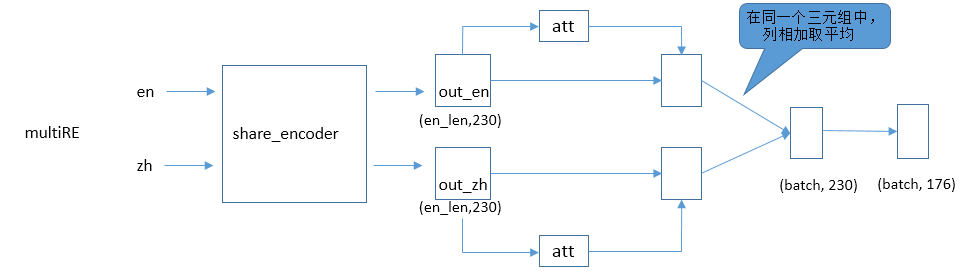
多语关系抽取
多语关系抽取会利用对抗网络中训练的参数。两种语言经过share_encoder进行特征的提取,然后使用注意力机制提取各自语言句子特征,最终合并成一个统一的向量进行关系分类。
单语关系抽取
单语关系抽取就是对各个语言进行独立的抽取,不会使用共享参数,经过词嵌入、卷积池化、注意力机制关系分类来预测结果。
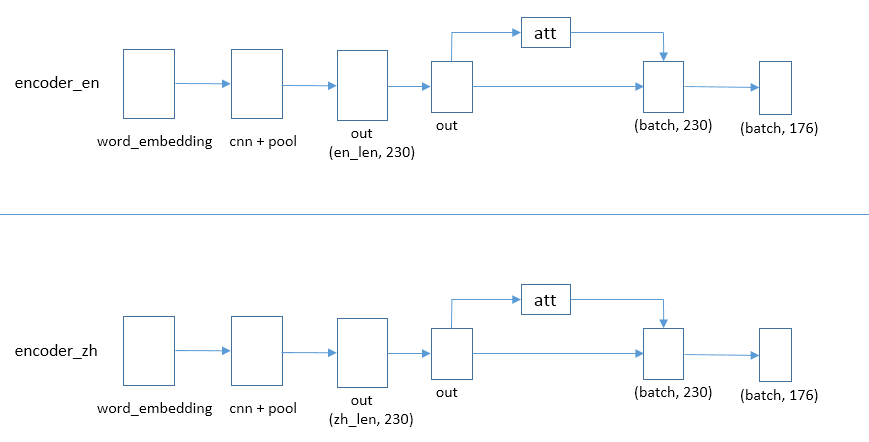
输出
输出是对176种关系进行分类预测
跨语言关系抽取
所以跨语言关系抽取就是结合单语与多语抽取结果作为最终的结果,进行反向传播,进行训练。