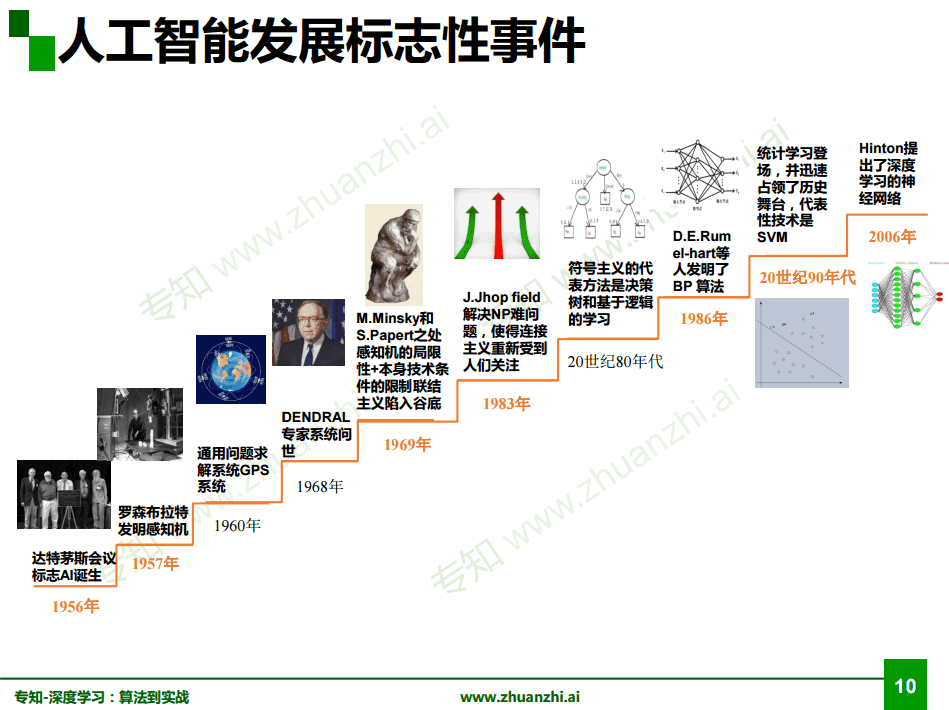
专知-绪论-人工智能起源
12 Jan 2019 | deep-learning |人工智能
使一部机器像人一样进行感知、认知、决策、执行的人工程序或系统。
图灵测试
如果一个人(代号C)使用测试对象皆理解的语言去询问两个他不能看见的对象任意一串问题。对象为:一个是正常思维的人(代号B)、一个是机器(代号A)。如果经过若干询问以后,C不能得出实质的区别来分辨A与B的不同,则此机器A通过图灵测试。
机器学习
计算机系统能够利用经验提高自身的性能
模型分类
1 数据标记
- 监督学习:数据标记已知,目的在于学习从输入到输出之间的映射
- 无监督学习:数据标记未知,目的在于发现数据中有意义的信息
- 半监督学习:部分数据已知,监督学习和无监督学习的混合
- 强化学习:数据标记未知,但是可以为输出目标提供反馈
2 数据分布
- 参数模型:对数据分开可以做出假设,选择一个模型(该模型的参数数目是有限且固定的)来刻画它
- 非参数模型:不对数据分布进行假设,数据的所有统计特性都来源于数据本身
3 建模对象
- 生成模型:对输入X和输出Y的联合分布P(X,Y)建模(先求联合分布p(x,y),然后利用贝叶斯公式求p(y|x))
- 判别模型:对已知输入X条件下输出Y的条件分布P(Y|X)建模(直接求p(y|x))
机器学习 VS 深度学习
- 基于规则的系统: 输入 –> 手动设计规则 –> 输出
- 传统机器学习: 输入 –> 手动设计特征 –> 特征映射 –> 输出
- 深度学习: 输入 –> 手动抽取简单特征 –> 神经网络抽取更复杂的特征–> 特征映射 –> 输出
深度学习的局限
- 输出不稳定,容易被攻击;对输入稍加改变就输出错误结果
- 模型复杂度高,难以调试和纠错;不易复现
- 模型层级复合程度高,参数不透明
- 端到端训练方式对数据依赖性强,模型增量性差;不好作为一个组件逐步加到系统中
- 专注直观感知类问题,对开放性推理问题无能为力
- 人类知识无法有效引入进行监督,机器偏见难以避免
人工智能发展史: