论文笔记Adversarial Multi-lingual Neural Relation Extraction
19 Nov 2018 | NLP |论文(Wang X, Han X, Lin Y, et al. Adversarial Multi-lingual Neural Relation Extraction[C]//Proceedings of the 27th International Conference on Computational Linguistics. 2018: 1156-1166.
) 使用对抗性神经网络来进行多语言的关系抽取。
论文的主要贡献:
- 使用对抗性网络来获取语言一致性信息
- 使用卷积网络来获取语言多样性信息
在表达同一种意思的时候,人们的表达形式是多种多样的,可以是声音,可以是手势,可以是图像,可以是文字。那么论文作者认为在不同语言之间也是存在语言一致性的,所以使用对抗网络来获取语言一致性信息。同时,不同语言本身是具有多样性的,所以还需考虑语言的多样性信息。
输入
语料是由汉语与英语构成的。一个示例由一个三元组,多个英语句子,多个汉语句子构成,这些句子共用同一个三元组。
Note:实体是可以用id来表示的,比如汉语“比利时”和英语“Belgium”对应同一个id:Q31
Instance:
(entity1, rel, entity2)
en:
sen_en1
sen_en2
sen_en3
zh:
sen_zh1
sen_zh2
网络架构
网络整体的架构包括单语关系抽取与多语关系抽取。
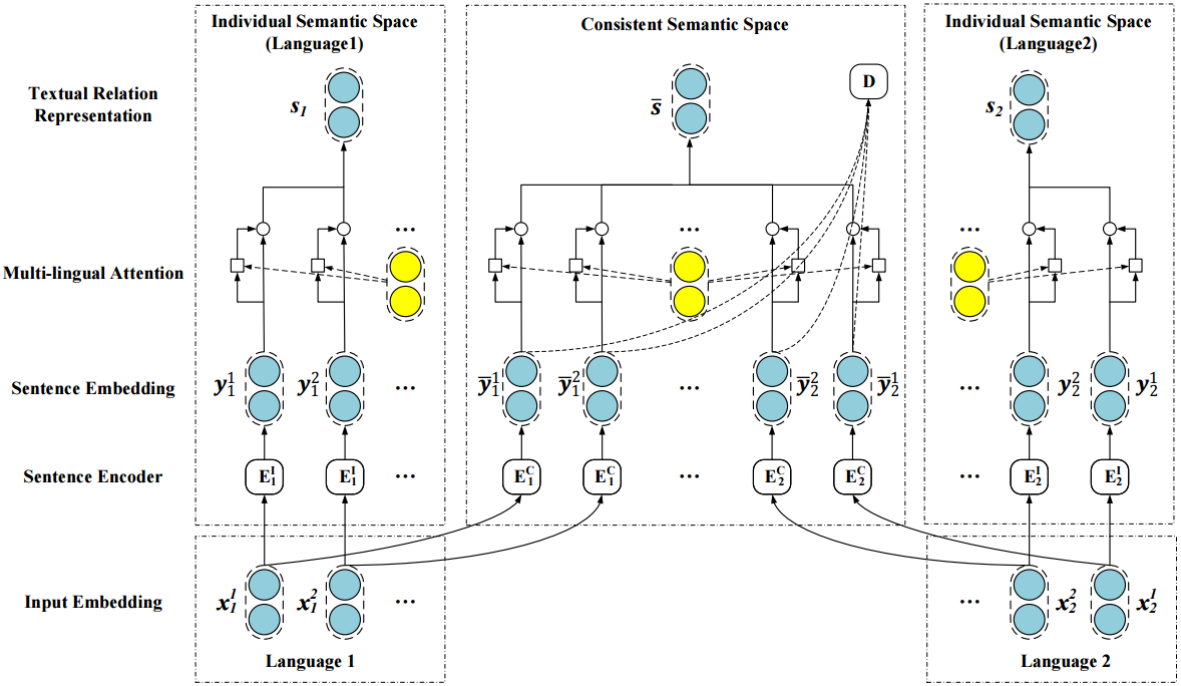
为了更加直观的理解模型,我画了一个参数模型。
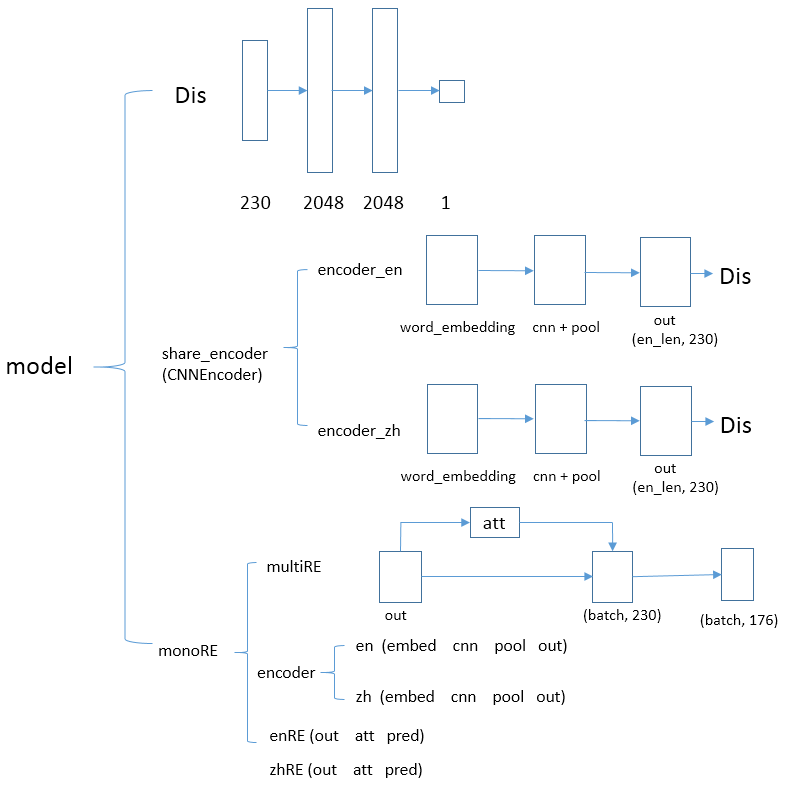
- 第一部分是判别器:判别器由多个线性层组成,用于区分语言(0代表英语,1代表汉语)
- 第二部分是卷积编码器:卷积编码器是为了抽取语言特征,将意义相同多种语言映射到同一个空间;它主要由词嵌入、卷积、池化操作构成
- 关系抽取:进行单语与多语的关系抽取
对抗网络
判别器:将语言进行卷积编码,然后输入到判别器,判别器的输出是0或者1,用于区分是哪一种语言; 欺骗器:将语言进行卷积编码,然后输入到判别器,让判别器的输出是1或者0,尽量不让判别器做出正确的区分。
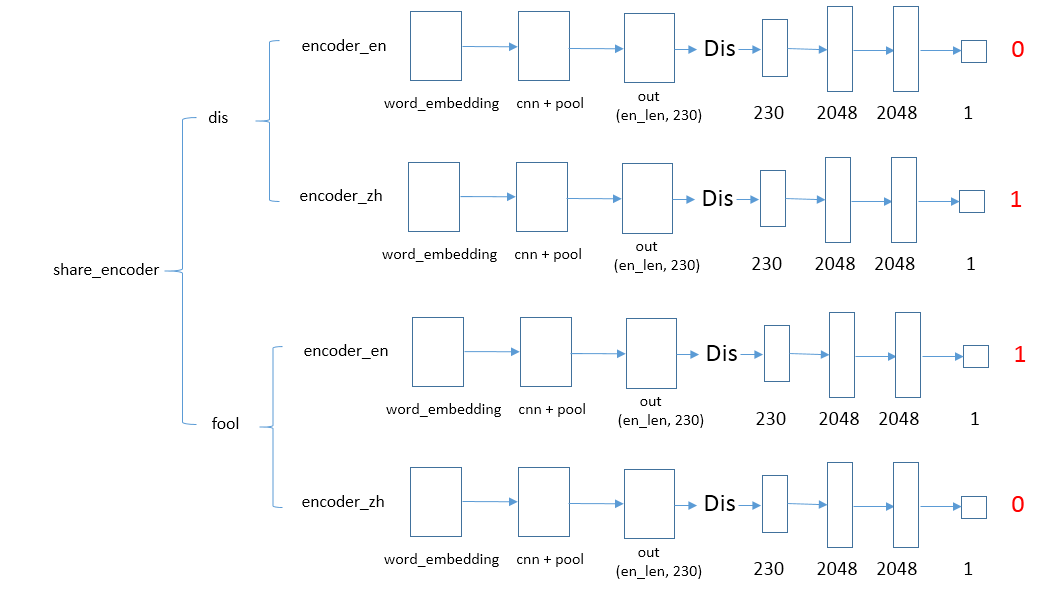
经上面反复的训练,对抗网络最终达到一个平衡的状态,无法区分出是哪一种语言了,效果就是:表达意义一样的多语句子映射到同一个空间的时候会很接近,不同意义的句子就会离的很远。
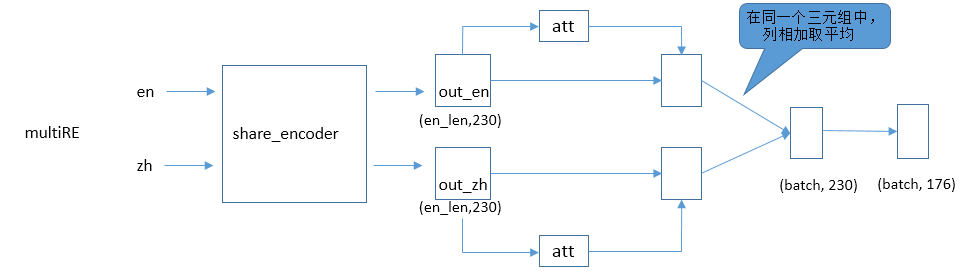
多语关系抽取
多语关系抽取会利用对抗网络中训练的参数。两种语言经过share_encoder进行特征的提取,然后使用注意力机制提取各自语言句子特征,最终合并成一个统一的向量进行关系分类。
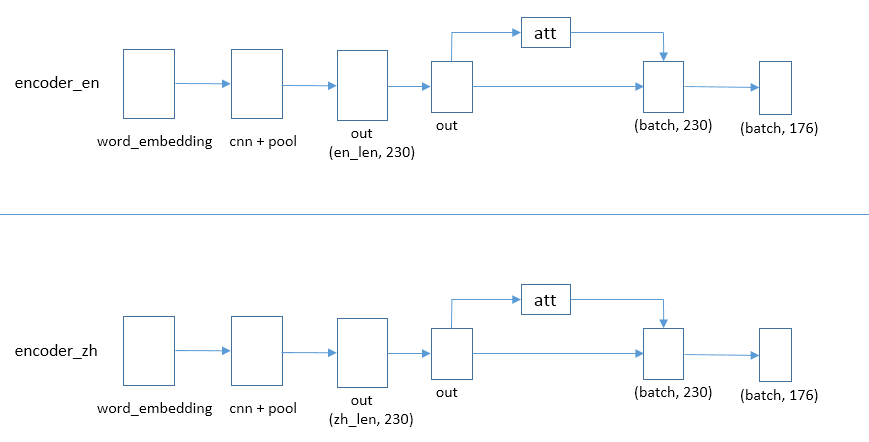
单语关系抽取
单语关系抽取就是对各个语言进行独立的抽取,不会使用共享参数,经过词嵌入、卷积池化、注意力机制关系分类来预测结果。
输出
输出是对176种关系进行分类预测
跨语言关系抽取
所以跨语言关系抽取就是结合单语与多语抽取结果作为最终的结果,进行反向传播,进行训练。