TextRank算法实现自动摘要
23 Sep 2018 | NLP |TextRank算法是根据PageRank改进而来的,关于PageRank算法你可以参考这里PageRank算法–从原理到实现
PageRank的计算公式:

PageRank的主要思想是用一个数值(PR值)来表示一个节点的重要层度,PR值的计算方式是对每个出度节点的PR值求平均,然后加上一个平滑的值,不断迭代进行求解。
TextRank的计算公式:
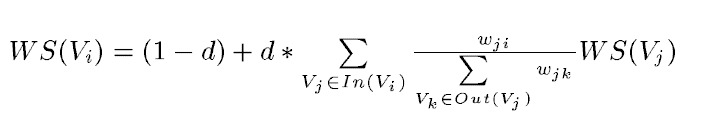
TextRank公式在PageRank的公式的基础上,引入了边的权值的概念,代表两个句子的相似度。
假设我现在有一段文字,如何进行自动摘要呢?
水利部水资源司司长陈明忠9月29日在国务院新闻办举行的新闻发布会上透露,
根据刚刚完成了水资源管理制度的考核,有部分省接近了红线的指标,
有部分省超过红线的指标。对一些超过红线的地方,陈明忠表示,
对一些取用水项目进行区域的限批,严格地进行水资源论证和取水许可的批准。;
HanLP中的自动摘要就是基于TextRank算法的,它的主要步骤如下:
- 句子划分
- 句子分词,转成doc对象
- TextRank自动摘要
- 获取前几个句子
/**
* @param document 目标文档
* @param size 需要的关键句的个数
* @param sentence_separator 句子分隔符,正则格式, 如:[。??!!;;]
* @return 关键句列表
*/
public static List<String> getTopSentenceList(String document, int size, String sentence_separator)
{
List<String> sentenceList = splitSentence(document, sentence_separator);//句子划分
List<List<String>> docs = convertSentenceListToDocument(sentenceList);//句子分词,转成doc对象
TextRankSentence textRank = new TextRankSentence(docs);//TextRank自动摘要
int[] topSentence = textRank.getTopSentence(size);//获取前几个句子
List<String> resultList = new LinkedList<String>();
for (int i : topSentence)
{
resultList.add(sentenceList.get(i));
}
return resultList;
}
句子划分
句子划分直接使用制定的分割符对整个句子进行切割就好了。
/**
* 将文章分割为句子
*
* @param document 待分割的文档
* @param sentence_separator 句子分隔符,正则表达式,如: [。:??!!;;]
* @return
*/
static List<String> splitSentence(String document, String sentence_separator)
{
List<String> sentences = new ArrayList<String>();
for (String line : document.split("[\r\n]"))
{
line = line.trim();
if (line.length() == 0) continue;
for (String sent : line.split(sentence_separator))//分割句子 [,,。::“”??!!;;]
{
sent = sent.trim();
if (sent.length() == 0) continue;
sentences.add(sent);
}
}
return sentences;
}
句子划分之后得到的结果:
sentenceList = {ArrayList@529} size = 8
0 = "水利部水资源司司长陈明忠9月29日在国务院新闻办举行的新闻发布会上透露"
1 = "根据刚刚完成了水资源管理制度的考核"
2 = "有部分省接近了红线的指标"
3 = "有部分省超过红线的指标"
4 = "对一些超过红线的地方"
5 = "陈明忠表示"
6 = "对一些取用水项目进行区域的限批"
7 = "严格地进行水资源论证和取水许可的批准"
句子分词,转成doc对象
对每个句子进行分词,会去掉一些停用词(因为这些词在句子中的作用不大,例如:的 地 得 这种词,对自动摘要的影响不大,需要去除)。
/**
* 将句子列表转化为文档
*
* @param sentenceList
* @return
*/
private static List<List<String>> convertSentenceListToDocument(List<String> sentenceList)
{
List<List<String>> docs = new ArrayList<List<String>>(sentenceList.size());
for (String sentence : sentenceList)
{
List<Term> termList = StandardTokenizer.segment(sentence.toCharArray());//句子分词,源码中用的维特比分词
List<String> wordList = new LinkedList<String>();
for (Term term : termList)
{
if (CoreStopWordDictionary.shouldInclude(term))//去掉停用词(常见的停用词直接写在字典里面了)
{
wordList.add(term.word);
}
}
docs.add(wordList);
}
return docs;
}
这一步得到的结果是:
docs = {ArrayList@539} size = 8
0 = "水利部" "水资源" "司" "司长" "陈明忠" "9月" "国务院新闻办" "举行" "新闻" "发布会" "透露"
1 = "刚刚" "完成" "水资源" "管理制度" "考核"
2 = "部分" "省" "接近" "红线" "指标"
3 = "部分" "省" "超过" "红线" "指标"
4 = "超过" "红线" "地方"
5 = "陈明忠" "表示"
6 = "取" "用水" "项目" "进行" "区域" "限"
7 = "严格" "进行" "水资源" "论证" "取水" "许可" "批准"
TextRank自动摘要
TextRank公式中需要计算权重w_ij,它描述了两个句子的相似度。计算方法可以使用BM25算法。
下面是HanLP中对BM25算法的一个实现:
/*
* <summary></summary>
* <author>He Han</author>
* <email>hankcs.cn@gmail.com</email>
* <create-date>2014/8/22 14:17</create-date>
*
* <copyright file="BM25.java" company="上海林原信息科技有限公司">
* Copyright (c) 2003-2014, 上海林原信息科技有限公司. All Right Reserved, http://www.linrunsoft.com/
* This source is subject to the LinrunSpace License. Please contact 上海林原信息科技有限公司 to get more information.
* </copyright>
*/
package com.hankcs.hanlp.summary;
import java.util.List;
import java.util.Map;
import java.util.TreeMap;
/**
* 搜索相关性评分算法
* @author hankcs
*/
public class BM25
{
/**
* 文档句子的个数
*/
int D;
/**
* 文档句子的平均长度
*/
double avgdl;
/**
* 拆分为[句子[单词]]形式的文档
*/
List<List<String>> docs;
/**
* 文档中每个句子中的每个词与词频
*/
Map<String, Integer>[] f;
/**
* 文档中全部词语与出现在几个句子中
*/
Map<String, Integer> df;
/**
* IDF
*/
Map<String, Double> idf;
/**
* 调节因子
*/
final static float k1 = 1.5f;
/**
* 调节因子
*/
final static float b = 0.75f;
public BM25(List<List<String>> docs)
{
this.docs = docs;
D = docs.size();//文档句子的个数
for (List<String> sentence : docs)
{
avgdl += sentence.size();
}
avgdl /= D; // 句子平均长度
f = new Map[D]; // 保存每一个句子中的 词与词频
df = new TreeMap<String, Integer>(); //保存所有的 词与词频
idf = new TreeMap<String, Double>();//保存所有词的逆文档频率
init();
}
/**
* 在构造时初始化自己的所有参数
*/
private void init()
{
int index = 0;
for (List<String> sentence : docs)//依次处理每一个句子
{
Map<String, Integer> tf = new TreeMap<String, Integer>();//保存词与词频
for (String word : sentence)
{
Integer freq = tf.get(word);
freq = (freq == null ? 0 : freq) + 1;
tf.put(word, freq);//保存词与词频
}
f[index] = tf; //保存每一个句子中的 词与词频
for (Map.Entry<String, Integer> entry : tf.entrySet())//计算所有的 词与词频
{
String word = entry.getKey();
Integer freq = df.get(word);
freq = (freq == null ? 0 : freq) + 1;
df.put(word, freq);//保存所有的 词与词频
}
++index;
}
for (Map.Entry<String, Integer> entry : df.entrySet())//计算所有词的逆文档频率
{
String word = entry.getKey();
Integer freq = entry.getValue();
idf.put(word, Math.log(D - freq + 0.5) - Math.log(freq + 0.5));//保存所有词的逆文档频率
}
}
//相似度计算:计算当前句子与某一个句子的相似度
public double sim(List<String> sentence, int index)
{
double score = 0;
for (String word : sentence)
{
if (!f[index].containsKey(word)) continue;//如果当前句子中不包含该词,则跳过
int d = docs.get(index).size();//当前句子的大小(包含多少个词)
Integer wf = f[index].get(word);//当前句子中的词的词频
score += (idf.get(word) * wf * (k1 + 1)
/ (wf + k1 * (1 - b + b * d
/ avgdl)));//BM25计算公式
}
return score;
}
//相似度计算:依次计算当前句子与文档中所有句子的相似度
public double[] simAll(List<String> sentence)
{
double[] scores = new double[D];//相似度评分
for (int i = 0; i < D; ++i)//依次计算当前句子与文档中所有句子的相似度
{
scores[i] = sim(sentence, i);
}
return scores;
}
}
上面的代码只是计算出了TextRank中的w_ij,接下来就是TextRank的实现了:
//TextRank的具体实现
private void solve()
{
int cnt = 0;
for (List<String> sentence : docs)
{
double[] scores = bm25.simAll(sentence);//计算一个句子和其他句子的相似度
weight[cnt] = scores; // 第cnt个句子与其他句子的相似度
weight_sum[cnt] = sum(scores) - scores[cnt]; // 减掉自己,自己跟自己肯定最相似
vertex[cnt] = 1.0;//初始TextRank值
++cnt;
}
//不断迭代,慢慢收敛
for (int _ = 0; _ < max_iter; ++_)
{
double[] m = new double[D];
double max_diff = 0;
for (int i = 0; i < D; ++i)
{
m[i] = 1 - d;
for (int j = 0; j < D; ++j)
{
if (j == i || weight_sum[j] == 0) continue;
m[i] += (d * weight[j][i] / weight_sum[j] * vertex[j]);//TextRank计算公式
}
double diff = Math.abs(m[i] - vertex[i]);
if (diff > max_diff)//记录每次变化最大的值
{
max_diff = diff;
}
}
vertex = m;//保存当前值,作为公式中上一次的值
if (max_diff <= min_diff) break;
}
// 我们来排个序吧(从大到小),方便后面的句子获取
for (int i = 0; i < D; ++i)
{
top.put(vertex[i], i);
}
}
TextRank算法计算结果是:
top = {TreeMap@924} size = 8
0 = {TreeMap$Entry@931} "1.349988008966875" -> "7"
1 = {TreeMap$Entry@932} "1.3342420985416243" -> "0"
2 = {TreeMap$Entry@933} "1.3197213990970156" -> "3"
3 = {TreeMap$Entry@934} "1.0274137158613745" -> "2"
4 = {TreeMap$Entry@935} "0.8364585720283898" -> "5"
5 = {TreeMap$Entry@936} "0.7696043981680054" -> "6"
6 = {TreeMap$Entry@937} "0.7097069222950998" -> "1"
7 = {TreeMap$Entry@938} "0.6528648850416094" -> "4"
从上面我们可以看到,第7个句子的TR值最高,即句子:"严格地进行水资源论证和取水许可的批准"
获取前几个句子
TextRank算法计算结束之后,就知道了每个句子的TR值,越大越好,所以,最终获取指定的个数句子就行(这里获取前3个句子)。
[严格地进行水资源论证和取水许可的批准,
水利部水资源司司长陈明忠9月29日在国务院新闻办举行的新闻发布会上透露,
有部分省超过红线的指标]