TextRank算法提取关键词
17 Sep 2018 | NLP |TextRank算法是根据PageRank改进而来的,关于PageRank算法你可以参考这里PageRank算法–从原理到实现
PageRank的计算公式:

PageRank的主要思想是用一个数值(PR值)来表示一个节点的重要层度,PR值的计算方式是对每个出度节点的PR值求平均,然后加上一个平滑的值,不断迭代进行求解。
TextRank的计算公式:
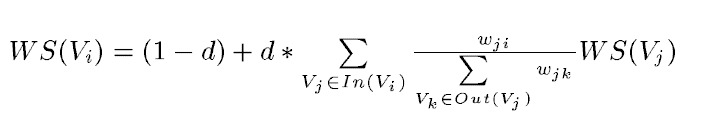
TextRank公式在PageRank的公式的基础上,引入了边的权值的概念,代表两个句子的相似度。
在用TextRank提取关键字的时候,实际上它退化成了PageRank算法,接下来,我们看看具体的实现,下面的实现是参考HanLP的。
假设我现在有一段文字,如何提取出里面的关键字呢?
程序员(英文Programmer)是从事程序开发、维护的专业人员。一般将程序员分为程序设计人员和程序编码人员,但两者的界限并不非常清楚,特别是在中国。
软件从业人员分为初级程序员、高级程序员、系统分析员和项目经理四大类。
首先对这句话分词,这里可以借助各种分词项目,比如HanLP分词,得出分词结果:
[程序员/nnt, (/w, 英文/nz, Programmer/nx, )/w, 是/vshi, 从事/vi, 程序/n, 开发/vn, 、/w, 维护/v, 的/ude1, 专业/n, 人员/n, 。/w, 一般/ad, 将/d, 程序员/nnt, 分为/v, 程序/n, 设计/vn, 人员/n, 和/cc, 程序/n, 编码/n, 人员/n, ,/w, 但/c, 两者/rzv, 的/ude1, 界限/n, 并不/d, 非常/d, 清楚/a, ,/w, 特别是在/l, 中国/ns, 。/w, 软件/n, 从业人员/nz, 分为/v, 初级/b, 程序员/nnt, 、/w, 高级/a, 程序员/nnt, 、/w, 系统分析员/nnt, 和/cc, 项目经理/nnt, 四大/n, 类/q, 。/w]
然后去掉里面的停用词,这里去掉了标点符号、常用词,最后只保留了名词、动词、形容词、副词。得出实际有用的词语:
[程序员, 英文, Programmer, 从事, 程序, 开发, 维护, 专业, 人员, 程序员, 分为, 程序, 设计, 人员, 程序, 编码, 人员, 界限, 并不, 非常, 清楚, 特别是在, 中国, 软件, 从业人员, 分为, 程序员, 高级, 程序员, 系统分析员, 项目经理, 四大]
之后建立两个大小为5的窗口,每个单词将票投给它身前身后距离5以内的单词:
{Programmer=[从事, 开发, 程序, 程序员, 维护, 英文],
专业=[人员, 从事, 分为, 开发, 程序, 程序员, 维护],
中国=[从业人员, 分为, 并不, 清楚, 特别是在, 程序员, 软件, 非常], 人员=[专业, 分为, 并不, 开发, 清楚, 界限, 程序, 程序员, 维护, 编码, 设计, 非常],
从业人员=[中国, 分为, 清楚, 特别是在, 程序员, 软件, 高级], 从事=[Programmer, 专业, 开发, 程序, 程序员, 维护, 英文],
分为=[专业, 中国, 人员, 从业人员, 特别是在, 程序, 程序员, 系统分析员, 维护, 设计, 软件, 高级],
四大=[程序员, 系统分析员, 项目经理, 高级],
并不=[中国, 人员, 清楚, 特别是在, 界限, 程序, 编码, 非常],
开发=[Programmer, 专业, 人员, 从事, 程序, 程序员, 维护, 英文],
清楚=[中国, 人员, 从业人员, 并不, 特别是在, 界限, 软件, 非常],
特别是在=[中国, 从业人员, 分为, 并不, 清楚, 界限, 软件, 非常],
界限=[人员, 并不, 清楚, 特别是在, 程序, 编码, 非常],
程序=[Programmer, 专业, 人员, 从事, 分为, 并不, 开发, 界限, 程序员, 维护, 编码, 英文, 设计],
程序员=[Programmer, 专业, 中国, 人员, 从业人员, 从事, 分为, 四大, 开发, 程序, 系统分析员, 维护, 英文, 设计, 软件, 项目经理, 高级], 系统分析员=[分为, 四大, 程序员, 项目经理, 高级],
维护=[Programmer, 专业, 人员, 从事, 分为, 开发, 程序, 程序员],
编码=[人员, 并不, 界限, 程序, 设计, 非常],
英文=[Programmer, 从事, 开发, 程序, 程序员],
设计=[人员, 分为, 程序, 程序员, 编码],
软件=[中国, 从业人员, 分为, 清楚, 特别是在, 程序员, 非常, 高级], 非常=[中国, 人员, 并不, 清楚, 特别是在, 界限, 编码, 软件],
项目经理=[四大, 程序员, 系统分析员, 高级],
高级=[从业人员, 分为, 四大, 程序员, 系统分析员, 软件, 项目经理]}
最后用PageRank算法进行计算,得到每个词的PR值,最后的结果是:
{特别是在=1.0015739, 程序员=2.0620303, 编码=0.78676623, 四大=0.6312981, 英文=0.6835063, 非常=1.0018439, 界限=0.88890904, 系统分析员=0.74232763, 从业人员=0.8993066, 程序=1.554001, 专业=0.88107216, 项目经理=0.6312981, 设计=0.6702926, 从事=0.9027207, Programmer=0.7930236, 软件=1.0078223, 人员=1.4288887, 清楚=0.9998723, 中国=0.99726284, 开发=1.0065585, 并不=0.9968608, 高级=0.9673803, 分为=1.4548829, 维护=0.9946941}
最后获取里面前5个最高的值作为关键字,即:[程序员, 程序, 分为, 人员, 软件]
。
rank算法的部分源码:
/**
* 使用已经分好的词来计算rank
*
* @param termList
* @return
*/
public Map<String, Float> getRank(List<Term> termList)
{
List<String> wordList = new ArrayList<String>(termList.size());
for (Term t : termList)
{
if (shouldInclude(t))//只保留 名词、动词、副词、形容词
{
wordList.add(t.word);
}
}
Map<String, Set<String>> words = new TreeMap<String, Set<String>>();//保存每个词的相邻词(邻接表)
Queue<String> que = new LinkedList<String>();//使用队列作为滑动窗口
for (String w : wordList)//获取各个词的窗口词,可以理解为图的邻接表
{
if (!words.containsKey(w))
{
words.put(w, new TreeSet<String>());
}
// 复杂度O(n-1)
if (que.size() >= 5)//使用队列作为滑动窗口
{
que.poll();
}
for (String qWord : que)
{
if (w.equals(qWord))//碰到一样的词,就不需要再放了
{
continue;
}
//既然是邻居,那么关系是相互的,遍历一遍即可
words.get(w).add(qWord);
words.get(qWord).add(w);
}
que.offer(w);
}
// System.out.println(words);
Map<String, Float> score = new HashMap<String, Float>();
//依据TF来设置初值
for (Map.Entry<String, Set<String>> entry : words.entrySet()){
score.put(entry.getKey(),sigMoid(entry.getValue().size()));
}
//开始迭代,不断收敛
for (int i = 0; i < max_iter; ++i)
{
Map<String, Float> m = new HashMap<String, Float>();//保存每次结果值
float max_diff = 0;
for (Map.Entry<String, Set<String>> entry : words.entrySet())
{
String key = entry.getKey();
Set<String> value = entry.getValue();
m.put(key, 1 - d);
for (String element : value)//根据公式进行计算(这里是抽取关键字,TextRank退化为PageRake)
{
int size = words.get(element).size();
if (key.equals(element) || size == 0) continue;
m.put(key, m.get(key) + d / size * (score.get(element) == null ? 0 : score.get(element)));
}
max_diff = Math.max(max_diff, Math.abs(m.get(key) - (score.get(key) == null ? 0 : score.get(key))));//出现迭代前后差值最大的值 都小于阈值就停止迭代
}
score = m;//作为下一次的初始值
if (max_diff <= min_diff) break; // 出现迭代前后差值最大的值 都小于阈值就停止迭代
}
return score;//最终的分数值
}