组织机构识别
15 Sep 2018 | NLP |组织机构的识别是在地名识别与人名识别之后进行的,它所使用的方式与地名、人名识别使用的方法是一样的,也是粗分句子、组织机构角色标注、选择最优角色、模式识别。
假设我现在有一个句子是:
我在上海林原科技有限公司兼职工作。
我们如何找出对它进行分词并找出里面的组织机构名称呢?
粗分句子
对原句使用维特比算法进行初步切分,得到如下结果:

然后进行人名地名的识别,得到如下结果:
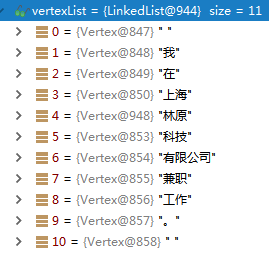
我们可以看到,经过上面的人名地名识别步骤,它识别出了林原是一个人名。好了,至此前面的操作我们认为都是粗分句子的步骤,接下来,是在粗分句子的基础之上进行真正的组织机构识别操作。
组织机构角色标注
这里的组织机构角色标注与之前的人名角色标注,地名角色标注所表示的意义是一样的,都是自定义的,为组织机构,地名,人名的识别打基础。那么,这里的组织机构角色标注集是这样的:
public enum NT
{
/**
* 上文 [参与]亚太经合组织的活动
*/
A,
/**
* 下文 中央电视台[报道]
*/
B,
/**
* 连接词 北京电视台[和]天津电视台
*/
X,
/**
* 特征词的一般性前缀 北京[电影]学院
*/
C,
/**
* 特征词的译名性前缀 美国[摩托罗拉]公司
*/
F,
/**
* 特征词的地名性前缀 交通银行[北京]分行
*/
G,
/**
* 特征词的机构名前缀 [中共中央]顾问委员会
*/
H,
/**
* 特征词的特殊性前缀 [华谊]医院
*/
I,
/**
* 特征词的简称性前缀 [巴]政府
*/
J,
/**
* 整个机构 [麦当劳]
*/
K,
/**
* 方位词
*/
L,
/**
* 数词 公交集团[五]分公司
*/
M,
/**
* 单字碎片
*/
P,
/**
* 符号
*/
W,
/**
* 机构名的特征词 国务院侨务[办公室]
*/
D,
/**
* 非机构名成份
*/
Z,
/**
* 句子的开头
*/
S
}
那么,如何对刚才的粗分结果进行角色标注呢?最主要的方式还是利用词典进行匹配。 组织机构的词典是这样的:
······
褐山 I 2
襄安 I 1
襄汾 I 1
西 L 100 A 20 B 15 X 1
西三旗 I 4
西乡 I 12
西二环 A 1
西侧 B 8 A 2
西元 I 1
······
每一行的规则是:词 词性A 词性A的词频 词性B 词性B的词频
比如西侧 B 8 A 2表示词西侧作为词性B(组织机构上文)在语料中出现的次数是8次,作为词性A(组织机构上文)在语料中出现的次数是2次。
那么,最后得到的角色标注结果就是:

选择最优角色
刚才的标注结果中,词可能有多个角色,我们需要选择出最优的角色,此处可以使用维特比算法选择最优角色,得到的结果是:

模式匹配
各个词选择了最优的角色,构成了一个词串SAAGFCDBABS,现在我们要做的事情就是给定一些模式,如何在现在的词串中找出给定的模式,这又是一个多模式匹配问题,和之前一样,采用AC自动机来解决这个问题。另外,这里的模式非常多,我在这里只是列出一部分:
......
GJGFJCD
GJGJCD
GJGJCJCD
GJGJCKDGD
GJGMCCD
GJGPCCCD
GJGPD
......
模式当然都是自己定义的,根据角色标注集,其中那些可以组成一个组织机构名,就把它写成一种模式。
在我们现在的字符串中SAAGFCDBABS,根据AC自动机进行多模式匹配,最终找出的模式有GFCD,FCD,CD。这三个模式分别对应的词组成的机构名称是上海林原科技有限公司, 林原科技有限公司,科技有限公司。
那么现在我们的分词结果可能是:
0:[ ]
1:[我]
2:[在, 在]
3:[上海, 上海林原科技有限公司, 上海]
4:[海]
5:[林原, 林原科技有限公司]
6:[原]
7:[科技, 科技有限公司]
8:[]
9:[有限公司]
10:[]
11:[]
12:[]
13:[兼, 兼职]
14:[]
15:[工作]
16:[]
17:[。]
18:[ ]
所以,再一次使用维特比算法求解,得到最优结果是:
[我, 在, 上海, 林原科技有限公司, 兼职, 工作。]