中国人名的识别
31 Aug 2018 | NLP |人名的识别是建立在初步分词的基础之上的。关于人名的详细描述(存在的问题,如何来做),请参考【基于角色标注的中国人名自动识别研究】这篇文章,里面写的很详细。
下面的内容是HanLP中的代码实现的个人解读,实现的核心思想还是根据上面的那篇文章来的,所以那篇文章应该好好看看。
HanLP人名识别
假设有一个例句:
签约仪式前,秦光荣、李纪恒、仇和等一同会见了参加签约的企业家。
我们要识别出其中的人名,应该怎么来做?
/**
* 中国人名识别
* @author hankcs
*/
public class DemoChineseNameRecognition
{
public static void main(String[] args)
{
String[] testCase = new String[]{
"签约仪式前,秦光荣、李纪恒、仇和等一同会见了参加签约的企业家。"
};
Segment segment = HanLP.newSegment().enableNameRecognize(true);//开启人名识别功能
for (String sentence : testCase)
{
List<Term> termList = segment.seg(sentence);
System.out.println(termList);
}
}
}
首先,进行初步分词,与之前介绍的方法一样(比如,可以使用简单的维特比分词)。 那么,我们得到的粗分结果如下:
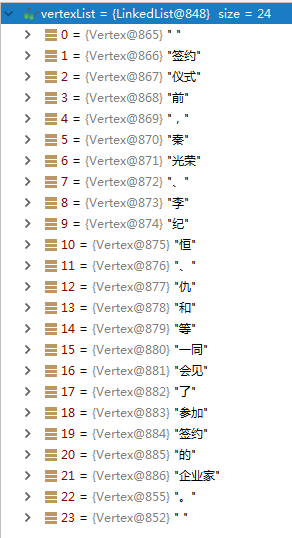
可以看到,粗分结果中,没有识别出其中的人名(秦光荣、李纪恒、仇和)。然后,使用用户自定义的词典,对粗分结果,进行调整。得到如下的结果:
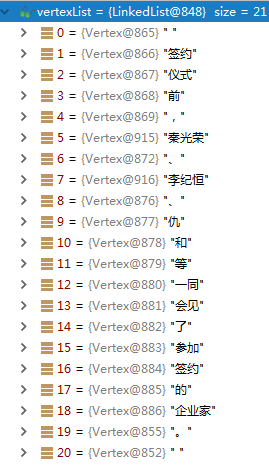
自定义的词典中如果有句子里面的人名,就可以直接匹配出来(DoubleArrayTrie加载词典,匹配字符)。但是,词典是有限的,并不能完全解决人名识别的问题,所以,上面这一步,也还没有识别出仇和这个人名,接下来,进入人名识别的具体方法。
人名识别
public static boolean recognition(List<Vertex> pWordSegResult, WordNet wordNetOptimum, WordNet wordNetAll)
{
List<EnumItem<NR>> roleTagList = roleObserve(pWordSegResult);//对粗分结果进行人名规则标记
List<NR> nrList = viterbiComputeSimply(roleTagList);//维特比找出最有可能的人名词性
PersonDictionary.parsePattern(nrList, pWordSegResult, wordNetOptimum, wordNetAll);//按照预定义的模式匹配标注的词性
return true;
}
上面主要分为了三个步骤,进行人名识别。在进入具体的实现时,先简要说一下,这里使用的人名规则。更具体的,请参考上面的论文。
一些字符表示的意义,即人名标签
/**
* 人名标签
* @author hankcs
*/
public enum NR
{
/**
* Pf 姓氏 【张】华平先生
*/
B,
/**
* Pm 双名的首字 张【华】平先生
*/
C,
/**
* Pt 双名的末字 张华【平】先生
*/
D,
/**
* Ps 单名 张【浩】说:“我是一个好人”
*/
E,
/**
* Ppf 前缀 【老】刘、【小】李
*/
F,
/**
* Plf 后缀 王【总】、刘【老】、肖【氏】、吴【妈】、叶【帅】
*/
G,
/**
* Pp 人名的上文 又【来到】于洪洋的家。
*/
K,
/**
* Pn 人名的下文 新华社记者黄文【摄】
*/
L,
/**
* Ppn 两个中国人名之间的成分 编剧邵钧林【和】稽道青说
*/
M,
/**
* Ppf 人名的上文和姓成词 这里【有关】天培的壮烈
*/
U,
/**
* Pnw 三字人名的末字和下文成词 龚学平等领导, 邓颖【超生】前
*/
V,
/**
* Pfm 姓与双名的首字成词 【王国】维、
*/
X,
/**
* Pfs 姓与单名成词 【高峰】、【汪洋】
*/
Y,
/**
* Pmt 双名本身成词 张【朝阳】
*/
Z,
/**
* Po 以上之外其他的角色
*/
A,
/**
* 句子的开头
*/
S,
}
人名词典,大概是这样的:
......
筹集 L 3
签 D 8 L 5 E 1 K 1
签单 L 2
签发 L 1
签名 L 36
签字 L 1
签完 L 4
签批 L 1
签约 L 10 K 7
......
每一行表示的意义是: 词 人名词性A A的频次 人名词性B B的频次
比如: 签约 L 10 K 7 表示词签约作为人名标签L(人名的下文)在语料中出现的次数是10次,作为人名标签K(人名的上文)在语料中出现的次数是7次。
还有一个二元词典描述的是人名标签之间的转移频次,A@A、A@B等等出现的频次。

角色观察roleObserve
角色观察所做的事情就是对粗分的结果,标注每个词的可能人名标签(用人名词典去匹配)。
/**
* 角色观察(从模型中加载所有词语对应的所有角色,允许进行一些规则补充)
* @param wordSegResult 粗分结果
* @return
*/
public static List<EnumItem<NR>> roleObserve(List<Vertex> wordSegResult)
{
List<EnumItem<NR>> tagList = new LinkedList<EnumItem<NR>>();
Iterator<Vertex> iterator = wordSegResult.iterator();
iterator.next();
tagList.add(new EnumItem<NR>(NR.A, NR.K)); // 始##始 A K
while (iterator.hasNext())
{
Vertex vertex = iterator.next();
EnumItem<NR> nrEnumItem = PersonDictionary.dictionary.get(vertex.realWord);//在人名词典中获取词的标签
if (nrEnumItem == null)//如果在词典中,不存在该词,做一些默认处理
{
//自己定义,默认处理....
}
tagList.add(nrEnumItem);//添加人名标签
}
return tagList;
}
角色观察得到的结果是:
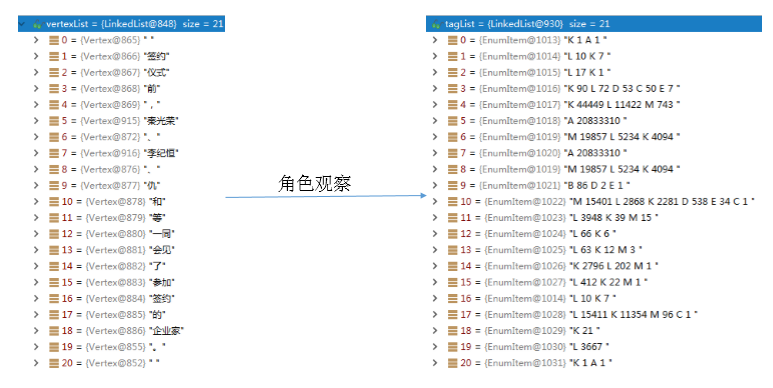
上面的左右图对照着看,就知道了每个词对应的可能人名标签。接着,就需要找出,这些标签中,每个词最有可能的标签是哪一个。
维特比
HanLP源码中使用了维特比算法(维特比算法在之前已经介绍过了)找最短路径,即找出每个词最有可能的人名标签,上面得到的结果中,一个词可能有多个人名标签。这一步得到的结果是:

模式解析
维特比解码之后,得到了每个词的人名标签词串KLLKKAKAKBELLLKLLLKLA,那么现在要做的事情就是根据自定义的模式在人名标签词串中找出存在的模式。
/**
* 人名识别模式串
*
* @author hankcs
*/
public enum NRPattern
{
BBCD,
BBE,
BBZ,
BCD,
BEE,
BE,
BC,
BEC,
BG,
DG,
EG,
BZ,
EE,
FE,
FC,
FB,
FG,
Y,
XD
}
人名识别模式串是自己定义的,认为按照这样的规则组合才能算是人名。比如BBCD 表示:姓氏 姓氏 双名的首字 双名的末字,这种规则可以认为是一种人名,其他模式是类似的。
现在的问题就是,存在一个字符串KLLKKAKAKBELLLKLLLKLA,有多个模式,如何在字符串中找出存在的模式呢?当然是用AC自动机了,来实现多模式匹配(HanLP使用的是基于双数组的AC自动机,之前已经介绍过了)。
那么,最终找出了模式BE在字符串KLLKKAKAKBELLLKLLLKLA中,所以BE对应的两个词是可以组合在一起形成一个人名的,即仇和是一个人名(B->仇,E->和 )。
那么最终的分词结果就是:
[签约, 仪式, 前, ,, 秦光荣, 、, 李纪恒, 、, 仇和, 等, 一同, 会见, 了, 参加, 签约, 的, 企业家, 。]
参考文献:
- 张华平,刘群.基于角色标注的中国人名自动识别研究[J].计算机学报,2004(01):85-91.
- 实战HMM-Viterbi角色标注中国人名识别
- HanLP人名识别示例