维特比(viterbi)分词
13 Aug 2018 | NLP |维特比(viterbi)分词是采用动态规划的思想进行最优分词,局部最优达到全局最优。
现在我们有语句需要进行分词:
有意见分歧。
首先,我们需要用准备好的词典对上述句子进行前缀划分,即找出每个词的所有可能情况。我们得到:
有/有意 , 意/意见 , 见 , 分/分歧 , 。
为了好处理,我们在开始与结尾各自加上一个节点,那么现在的结果是这样的:

接下来就可以使用维特比算法找出最优路径。
刚开始,节点都没有连接,那么从第0列到第1列(即从 start 到有/有意),就直接相连了。此时,我们最新的情况就是这样的了:

然后,处理第1列到第2列(即从 有/有意 到意/意见);先来处理有 到意/意见,他们之间也还没有相连,我们直接连接起来就行,那么现在的图是这样的了:

接着处理有意 到见(注意,此时跳到了第3列,因为,有意不能再和意/意见,相连,否则就重复了。具体跳到那一列,是根据当前词的长度来决定的,你可以查看源码。),那么此时的图就是这样的了:
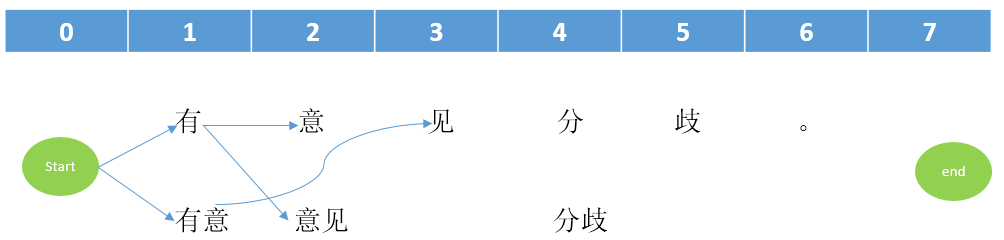
现在,我们需要处理第2列到第3列了(即从意/意见到见),现在节点见的前面已经有节点有意了,我们需要判断意 --> 见与有意-->见哪一个权重值更小(权重的计算,请看源码,计算出来的结果是有意-->见权重值更小,所以意 --> 见不相连,节点见不更新。所以现在的情况跟之前一样。
然后是有意和分/分歧 直接相连(因为他们还没有跟其他节点连接)。此时图的情况是这样的:
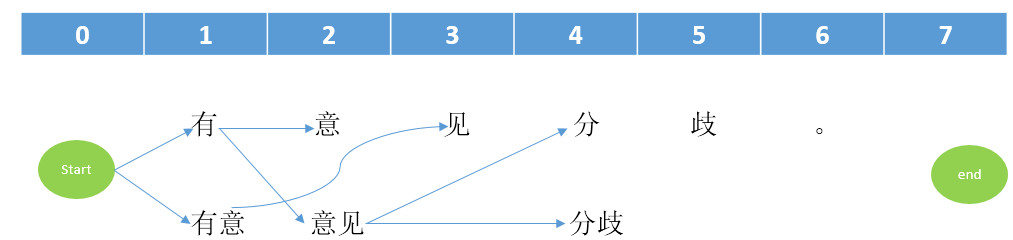
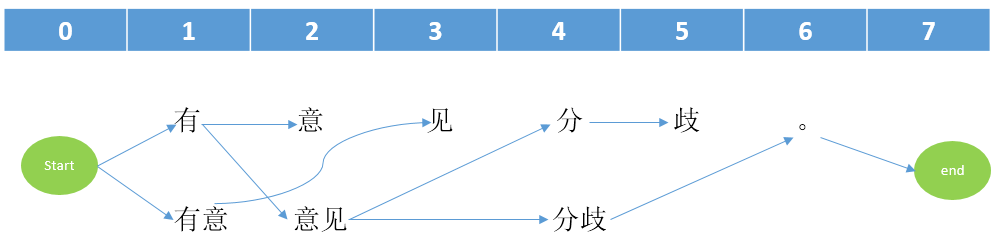
按照上面的方式继续处理后面的节点(没有连接的直接相连;已经被连接的就判断当前的连接与之前的连接哪一个权重值更小,保留小的连接),我们可以得到最终的图连接情况。
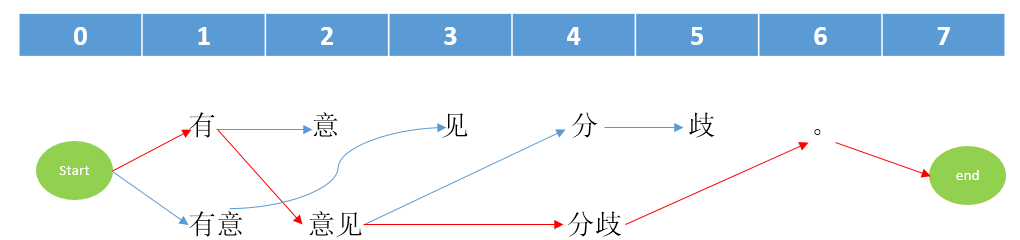
然后从最后一个开始反向回溯,依次找到每个节点的前节点,我们可以得到最终的分词:
HanLP维特比分词源码
private static List<Vertex> viterbi(WordNet wordNet)
{
LinkedList<Vertex> nodes[] = wordNet.getVertexes();
LinkedList<Vertex> vertexList = new LinkedList<Vertex>();
for (Vertex node : nodes[1])//更新起始节点
{
node.updateFrom(nodes[0].getFirst());
}
for (int i = 1; i < nodes.length - 1; ++i)//遍历节点
{
LinkedList<Vertex> nodeArray = nodes[i];
if (nodeArray == null) continue;
for (Vertex node : nodeArray)//遍历当前所有前缀节点
{
if (node.from == null) continue;
for (Vertex to : nodes[i + node.realWord.length()])//遍历当前节点的后继节点,具体跳到那一列
{
to.updateFrom(node);//节点权重更新
}
}
}
Vertex from = nodes[nodes.length - 1].getFirst();//获取最后一个节点
while (from != null)//反向回溯
{
vertexList.addFirst(from);
from = from.from;
}
return vertexList;
}
/*--------节点权重更新--------*/
public void updateFrom(Vertex from)
{
//计算权重,源码中的计算方式采用了-log(p),所以频率越大,权重值越小。
double weight = from.weight + MathUtility.calculateWeight(from, this);
if (this.from == null || this.weight > weight)//选择更小权重的节点
{
this.from = from;
this.weight = weight;
}
}
参考资源: