序列到序列
09 Jun 2018 | deep-learning |序列到序列
这一次我们将要构建一个序列到序列的神经网络,文章来源与udacity
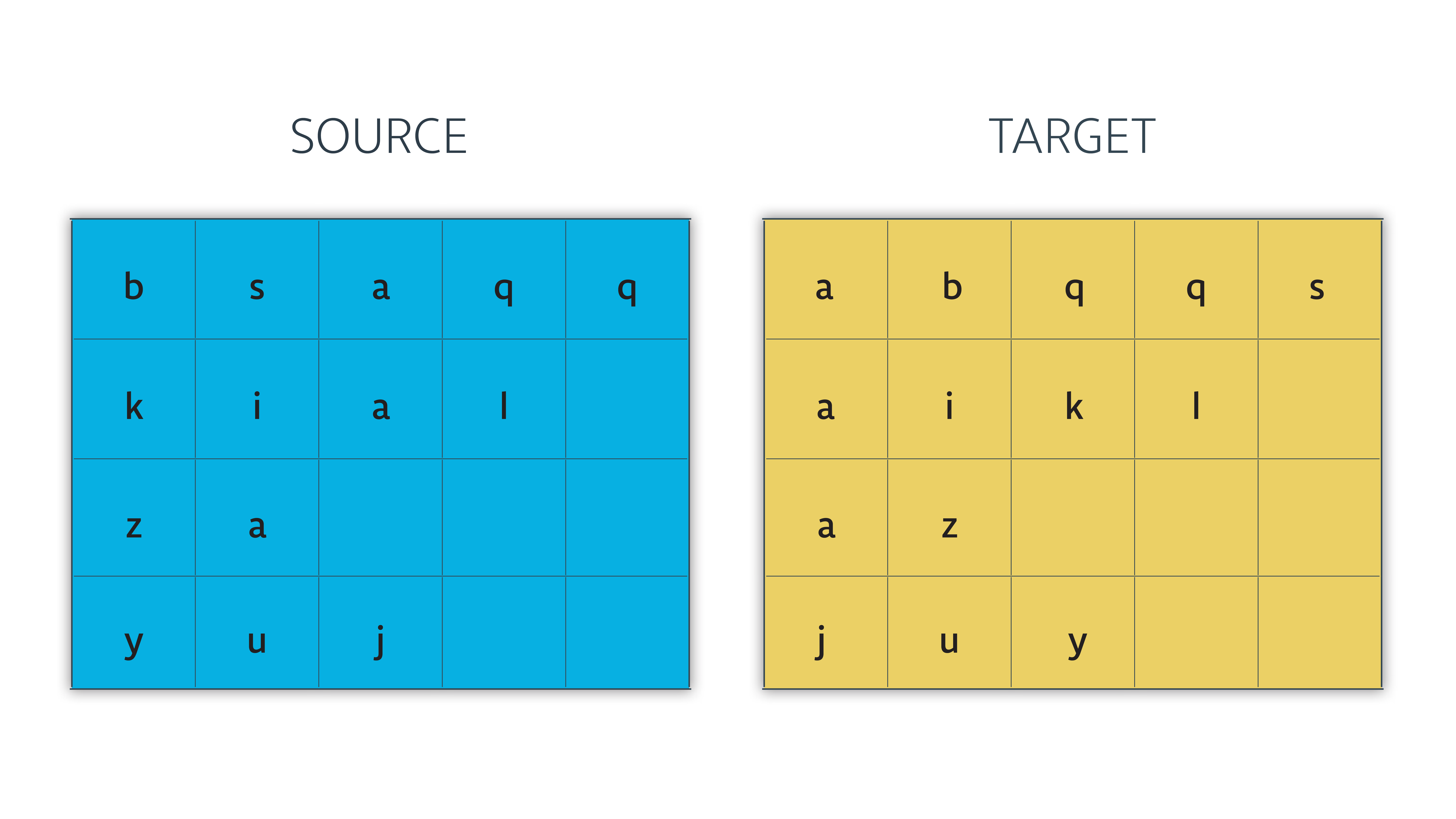
数据集
数据集包括一个源文件和一个目标文件,他们一一对应。
import numpy as np
import time
import helper
source_path = 'data/letters_source.txt'
target_path = 'data/letters_target.txt'
source_sentences = helper.load_data(source_path)
target_sentences = helper.load_data(target_path)
source_sentences[:50].split('\n')
['bsaqq',
'npy',
'lbwuj',
'bqv',
'kial',
'tddam',
'edxpjpg',
'nspv',
'huloz',
'']
target_sentences 是source_sentences中每一个字符的有序排列结果。
target_sentences[:50].split('\n')
['abqqs',
'npy',
'bjluw',
'bqv',
'aikl',
'addmt',
'degjppx',
'npsv',
'hlouz',
'']
预处理
将字符串转化为一个字符序列
def extract_character_vocab(data):
special_words = ['<PAD>', '<UNK>', '<GO>', '<EOS>']
set_words = set([character for line in data.split('\n') for character in line])
int_to_vocab = {word_i: word for word_i, word in enumerate(special_words + list(set_words))}
vocab_to_int = {word: word_i for word_i, word in int_to_vocab.items()}
return int_to_vocab, vocab_to_int
# Build int2letter and letter2int dicts
source_int_to_letter, source_letter_to_int = extract_character_vocab(source_sentences)
target_int_to_letter, target_letter_to_int = extract_character_vocab(target_sentences)
# Convert characters to ids
source_letter_ids = [[source_letter_to_int.get(letter, source_letter_to_int['<UNK>']) for letter in line] for line in source_sentences.split('\n')]
target_letter_ids = [[target_letter_to_int.get(letter, target_letter_to_int['<UNK>']) for letter in line] + [target_letter_to_int['<EOS>']] for line in target_sentences.split('\n')]
print("Example source sequence")
print(source_letter_ids[:3])
print("\n")
print("Example target sequence")
print(target_letter_ids[:3])
Example source sequence
[[28, 12, 16, 9, 9], [22, 4, 5], [8, 28, 20, 6, 19]]
Example target sequence
[[16, 28, 9, 9, 12, 3], [22, 4, 5, 3], [28, 19, 8, 6, 20, 3]]
print(source_sentences[:20])
print(target_letter_to_int)
bsaqq
npy
lbwuj
bqv
{'<PAD>': 0, '<UNK>': 1, '<GO>': 2, '<EOS>': 3, 'p': 4, 'y': 5, 'u': 6, 'x': 7, 'l': 8, 'q': 9, 't': 10, 'g': 11, 's': 12, 'h': 13, 'c': 14, 'r': 15, 'a': 16, 'd': 17, 'o': 18, 'j': 19, 'w': 20, 'v': 21, 'n': 22, 'i': 23, 'e': 24, 'z': 25, 'f': 26, 'm': 27, 'b': 28, 'k': 29}
上面的操作完成了字符到数值的转化。
模型
from distutils.version import LooseVersion
import tensorflow as tf
from tensorflow.python.layers.core import Dense
# Check TensorFlow Version
assert LooseVersion(tf.__version__) >= LooseVersion('1.1'), 'Please use TensorFlow version 1.1 or newer'
print('TensorFlow Version: {}'.format(tf.__version__))
TensorFlow Version: 1.1.0
超参数
# Number of Epochs
epochs = 60
# Batch Size
batch_size = 128
# RNN Size
rnn_size = 50
# Number of Layers
num_layers = 2
# Embedding Size
encoding_embedding_size = 15
decoding_embedding_size = 15
# Learning Rate
learning_rate = 0.001
输入
def get_model_inputs():
input_data = tf.placeholder(tf.int32, [None, None], name='input')
targets = tf.placeholder(tf.int32, [None, None], name='targets')
lr = tf.placeholder(tf.float32, name='learning_rate')
target_sequence_length = tf.placeholder(tf.int32, (None,), name='target_sequence_length')
max_target_sequence_length = tf.reduce_max(target_sequence_length, name='max_target_len')
source_sequence_length = tf.placeholder(tf.int32, (None,), name='source_sequence_length')
return input_data, targets, lr, target_sequence_length, max_target_sequence_length, source_sequence_length
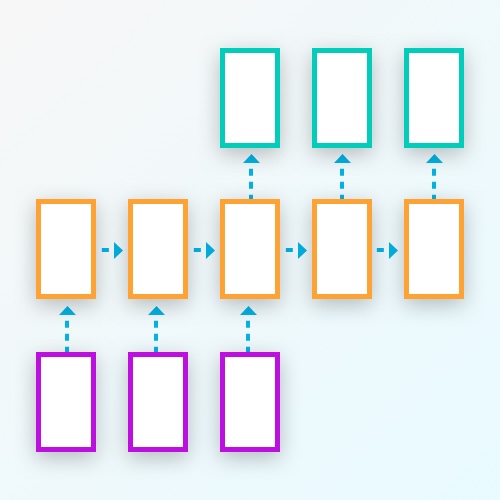
序列到序列模型
我们使用下列各个组件来构建seq2seq模型:
2.1 Encoder
- Embedding
- Encoder cell
2.2 Decoder
1- Process decoder inputs
2- Set up the decoder
- Embedding
- Decoder cell
- Dense output layer
- Training decoder
- Inference decoder
2.3 Seq2seq model connecting the encoder and decoder
2.4 Build the training graph hooking up the model with the
optimizer
2.1 编码器
首先我们需要构建的是编码器,将数据进行嵌入处理,作为编码器的输入。
- 嵌入数据你可以使用
tf.contrib.layers.embed_sequence
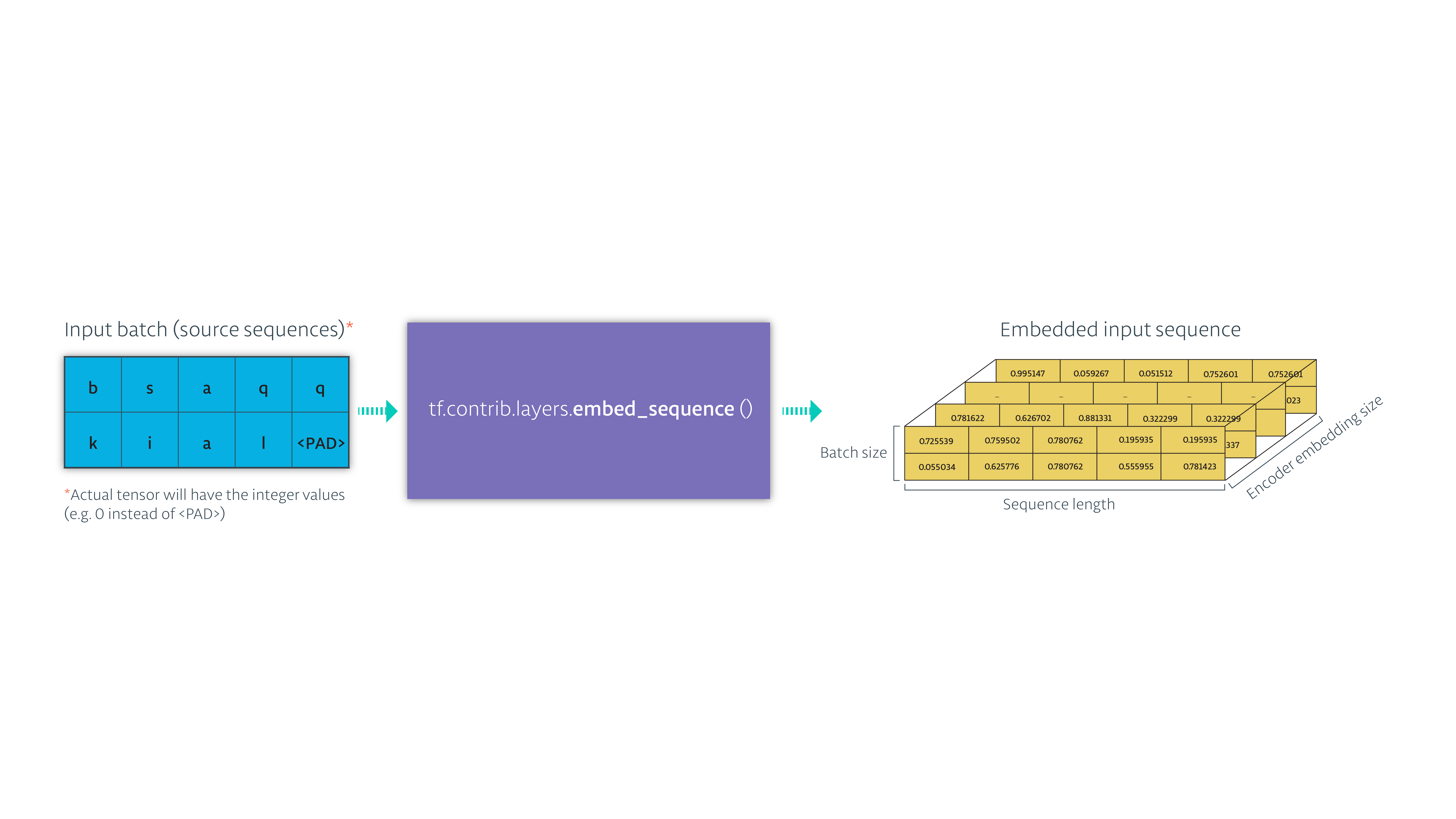
- 将编码的输入传入到RNN,得到隐藏状态和各个时刻的输出,我们不需要每个时刻的输出,忽略就行,只要最终的隐藏状态,它包含了当前整个输入序列的信息。
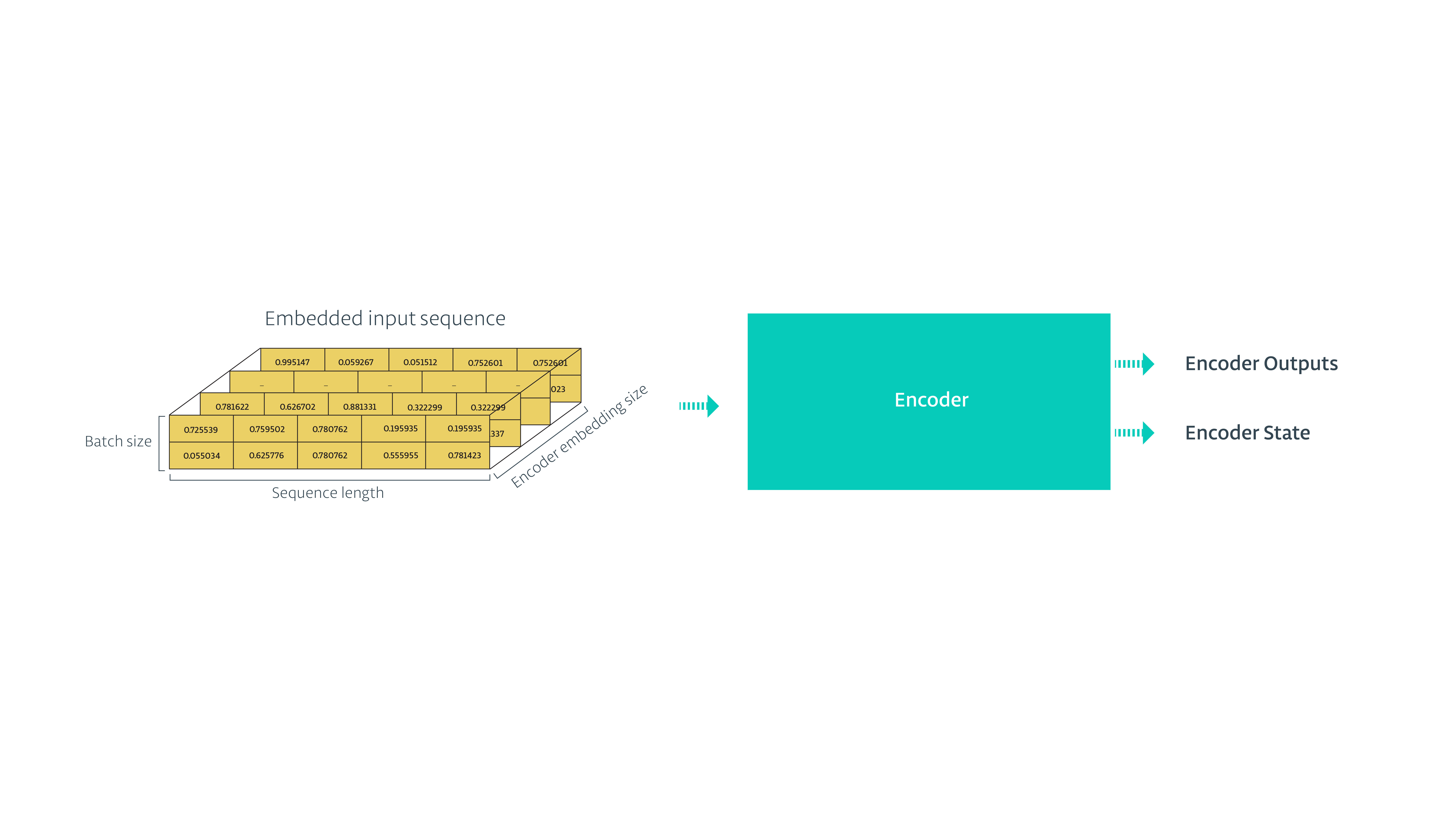
def encoding_layer(input_data, rnn_size, num_layers,
source_sequence_length, source_vocab_size,
encoding_embedding_size):
# Encoder embedding
enc_embed_input = tf.contrib.layers.embed_sequence(input_data, source_vocab_size, encoding_embedding_size)
# RNN cell
def make_cell(rnn_size):
enc_cell = tf.contrib.rnn.LSTMCell(rnn_size,
initializer=tf.random_uniform_initializer(-0.1, 0.1, seed=2))
return enc_cell
enc_cell = tf.contrib.rnn.MultiRNNCell([make_cell(rnn_size) for _ in range(num_layers)])
enc_output, enc_state = tf.nn.dynamic_rnn(enc_cell, enc_embed_input, sequence_length=source_sequence_length, dtype=tf.float32)
return enc_output, enc_state
2.2 解码器
解码器主要由以下部分构成: 1- Process decoder inputs 2- Set up the decoder components - Embedding - Decoder cell - Dense output layer - Training decoder - Inference decoder
处理解码输入
我们传入的输入是这样的(在代码中是整数数值,这里只是为了演示,所以用的是字符):
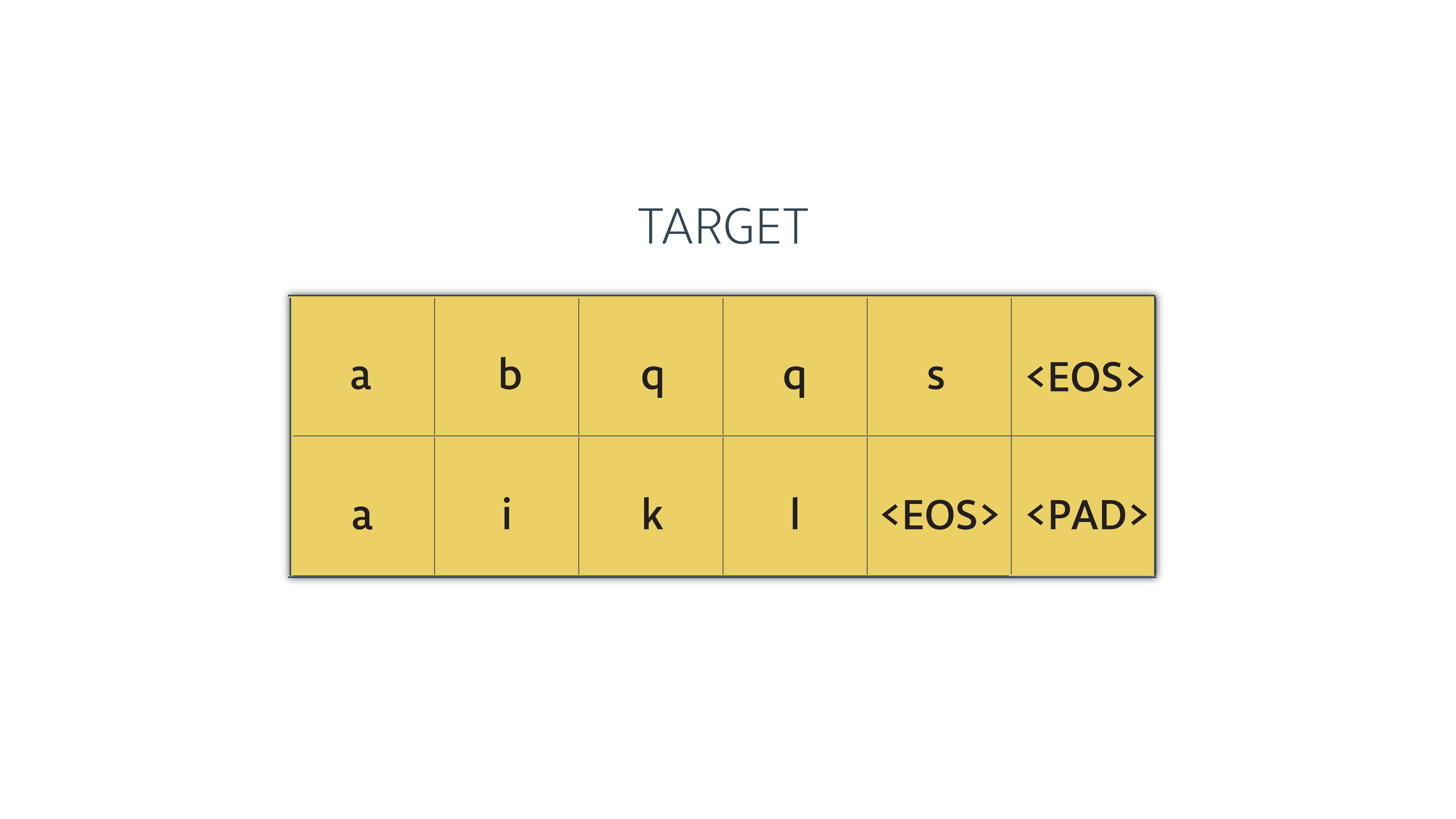 我们需要截断最后一个字符,因为,它不会被处理,
我们需要截断最后一个字符,因为,它不会被处理,tf.strided_slice()可以达到我们想要的目的。处理之后就是这样的了:
 然后,我们还需要加上一个开始处理的标识符:
然后,我们还需要加上一个开始处理的标识符:

 那么最终的输入就是这样的:
那么最终的输入就是这样的:

# Process the input we'll feed to the decoder
def process_decoder_input(target_data, vocab_to_int, batch_size):
'''Remove the last word id from each batch and concat the <GO> to the begining of each batch'''
ending = tf.strided_slice(target_data, [0, 0], [batch_size, -1], [1, 1])
dec_input = tf.concat([tf.fill([batch_size, 1], vocab_to_int['<GO>']), ending], 1)
return dec_input
Set up the decoder components
- Embedding
- Decoder cell
- Dense output layer
- Training decoder
- Inference decoder
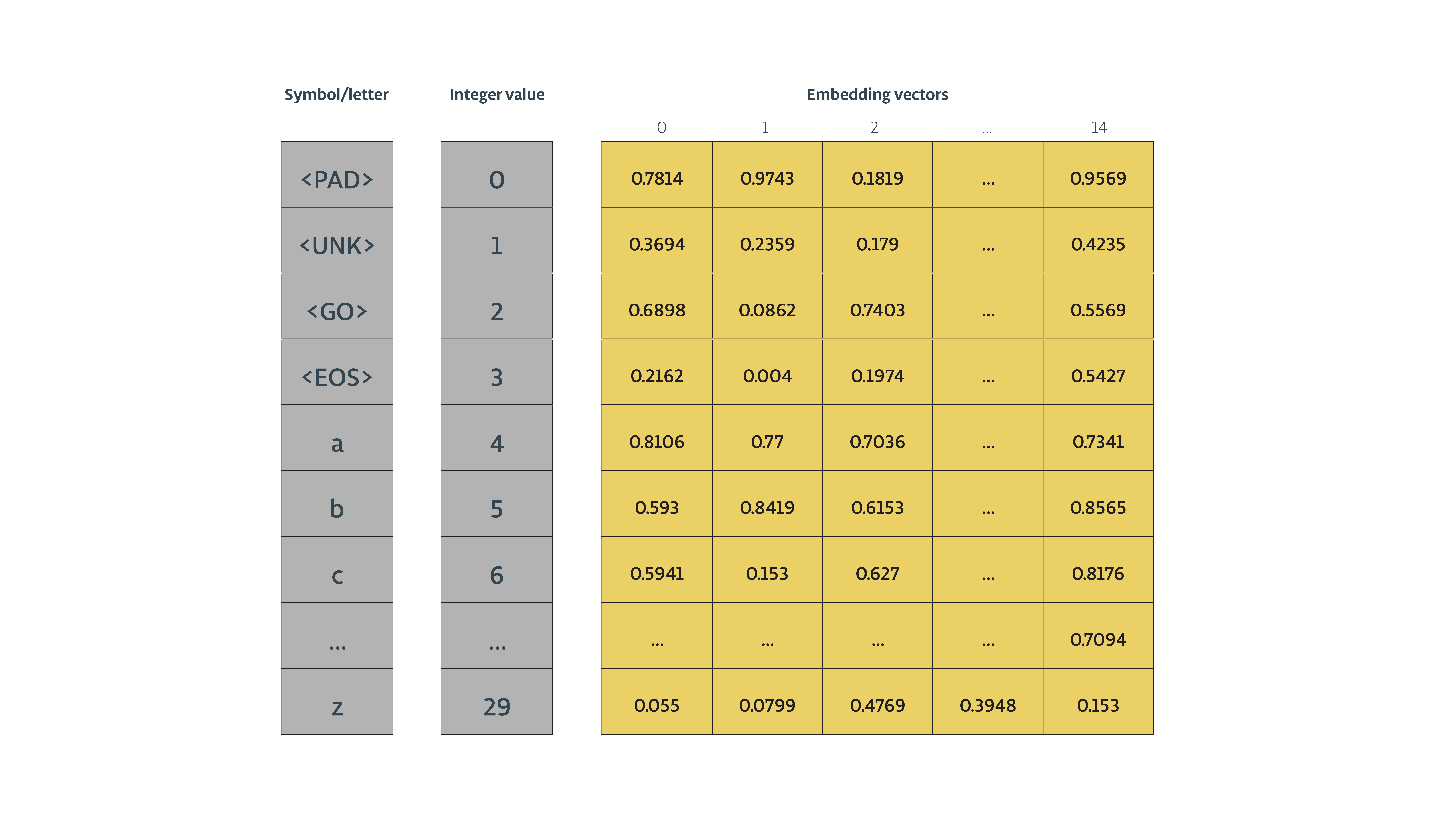
1- Embedding
将一个数值转化为一个向量,可以直接使用tf.nn.embedding_lookup来实现:
2- Decoder Cell
编码单元与解码单元是一致的。
3- Dense output layer
最后我们需要用全连接的方式处理decoder的输出。
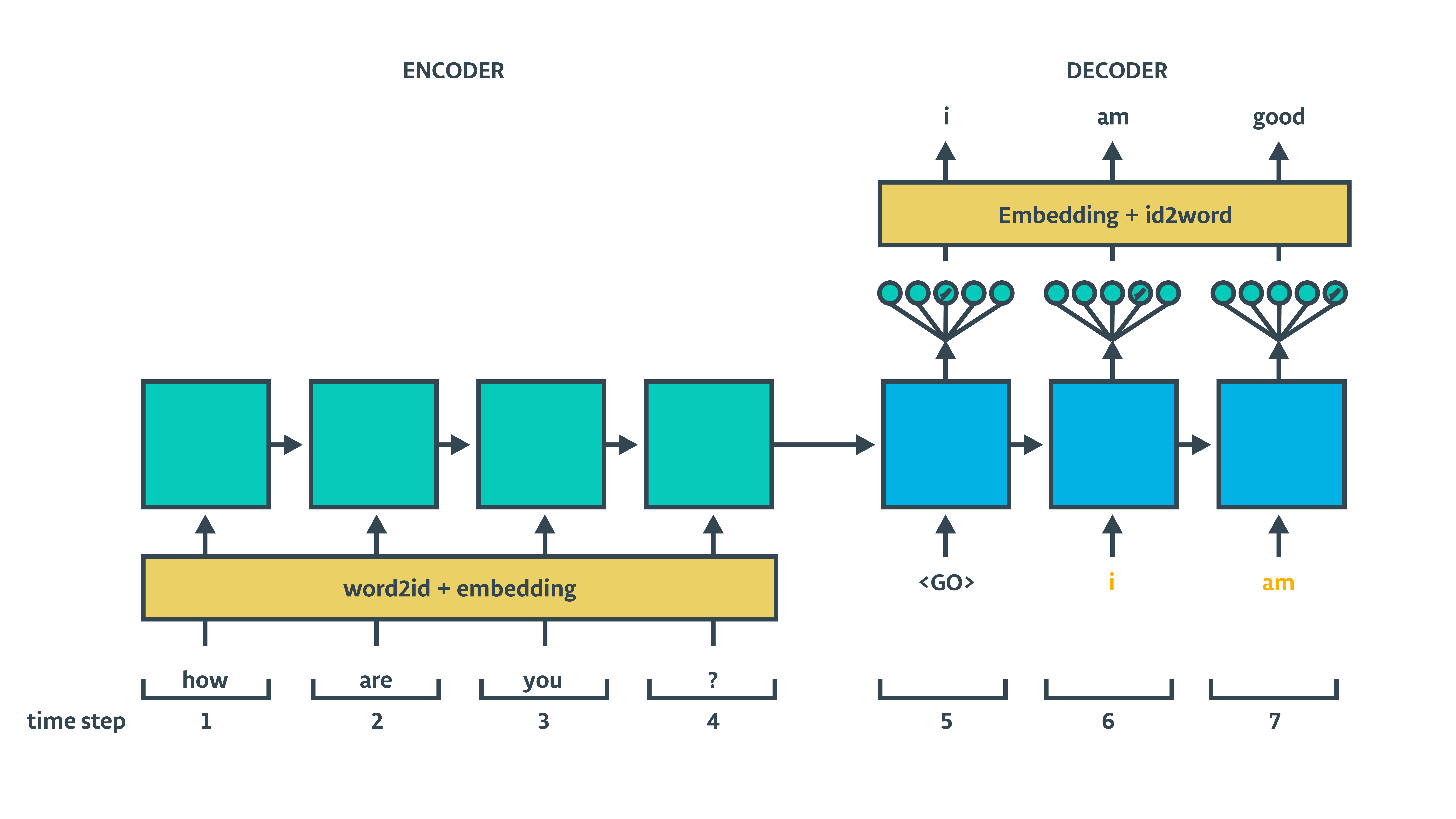
4- Training decoder
在训练期间使用的Training decoder,它需要target作为输入:
5- Inference decoder
在推断(预测)时使用的Inference decoder,ta的输入来自于上一时刻的输出:
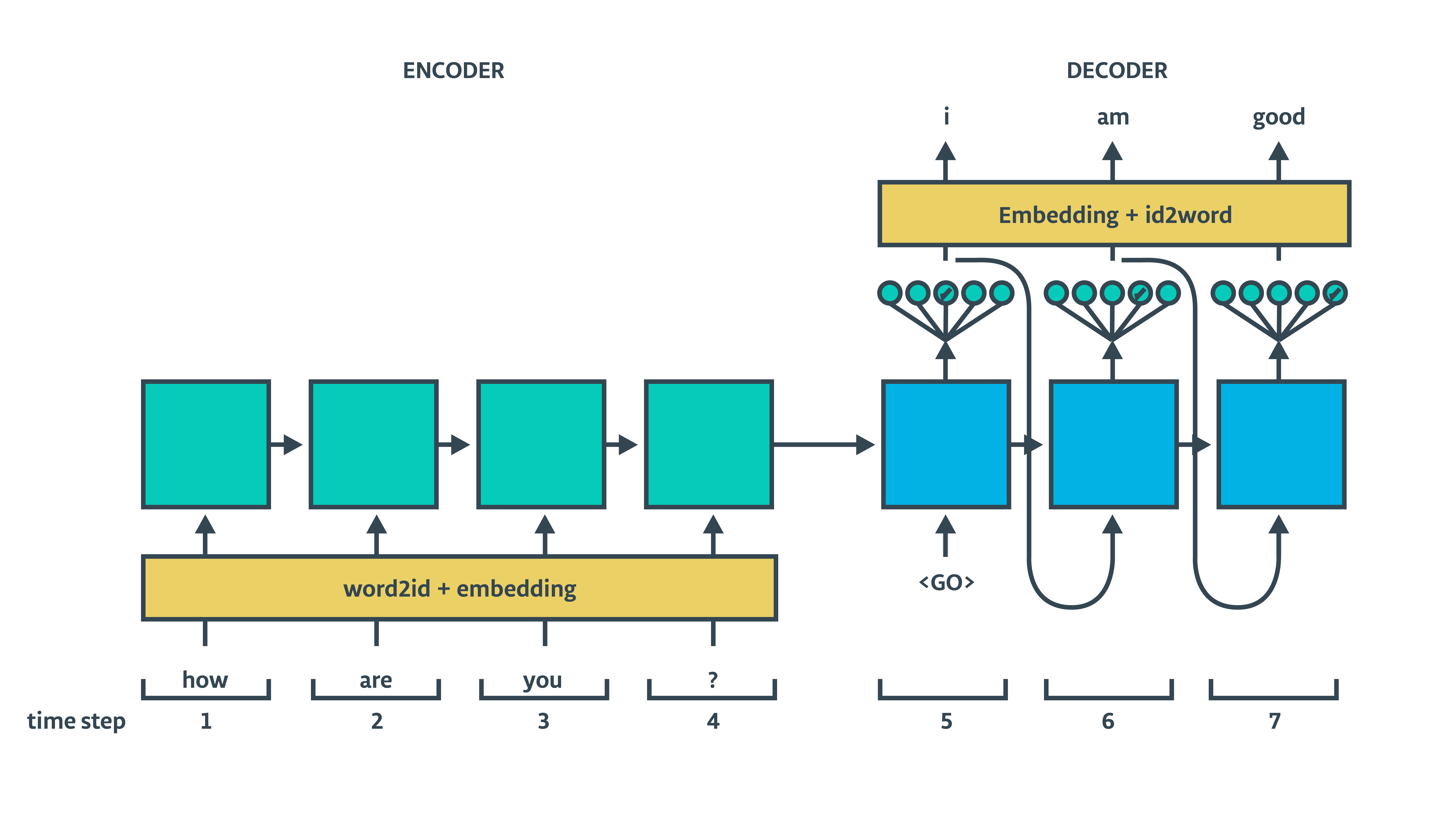
Training decoder 和Inference decoder 使用的参数是一样的,它们共享参数,隐藏状态来自于编码器。
def decoding_layer(target_letter_to_int, decoding_embedding_size, num_layers, rnn_size,
target_sequence_length, max_target_sequence_length, enc_state, dec_input):
# 1. Decoder Embedding
target_vocab_size = len(target_letter_to_int)
dec_embeddings = tf.Variable(tf.random_uniform([target_vocab_size, decoding_embedding_size]))
dec_embed_input = tf.nn.embedding_lookup(dec_embeddings, dec_input)
# 2. Construct the decoder cell
def make_cell(rnn_size):
dec_cell = tf.contrib.rnn.LSTMCell(rnn_size,
initializer=tf.random_uniform_initializer(-0.1, 0.1, seed=2))
return dec_cell
dec_cell = tf.contrib.rnn.MultiRNNCell([make_cell(rnn_size) for _ in range(num_layers)])
# 3. Dense layer to translate the decoder's output at each time
# step into a choice from the target vocabulary
output_layer = Dense(target_vocab_size,
kernel_initializer = tf.truncated_normal_initializer(mean = 0.0, stddev=0.1))
# 4. Set up a training decoder and an inference decoder
# Training Decoder
with tf.variable_scope("decode"):
# Helper for the training process. Used by BasicDecoder to read inputs.
training_helper = tf.contrib.seq2seq.TrainingHelper(inputs=dec_embed_input,
sequence_length=target_sequence_length,
time_major=False)
# Basic decoder
training_decoder = tf.contrib.seq2seq.BasicDecoder(dec_cell,
training_helper,
enc_state,
output_layer)
# Perform dynamic decoding using the decoder
training_decoder_output = tf.contrib.seq2seq.dynamic_decode(training_decoder,
impute_finished=True,
maximum_iterations=max_target_sequence_length)[0]
# 5. Inference Decoder
# Reuses the same parameters trained by the training process
with tf.variable_scope("decode", reuse=True):
start_tokens = tf.tile(tf.constant([target_letter_to_int['<GO>']], dtype=tf.int32), [batch_size], name='start_tokens')
# Helper for the inference process.
inference_helper = tf.contrib.seq2seq.GreedyEmbeddingHelper(dec_embeddings,
start_tokens,
target_letter_to_int['<EOS>'])
# Basic decoder
inference_decoder = tf.contrib.seq2seq.BasicDecoder(dec_cell,
inference_helper,
enc_state,
output_layer)
# Perform dynamic decoding using the decoder
inference_decoder_output = tf.contrib.seq2seq.dynamic_decode(inference_decoder,
impute_finished=True,
maximum_iterations=max_target_sequence_length)[0]
return training_decoder_output, inference_decoder_output
2.3 Seq2Seq 模型
def seq2seq_model(input_data, targets, lr, target_sequence_length,
max_target_sequence_length, source_sequence_length,
source_vocab_size, target_vocab_size,
enc_embedding_size, dec_embedding_size,
rnn_size, num_layers):
# Pass the input data through the encoder. We'll ignore the encoder output, but use the state
_, enc_state = encoding_layer(input_data,
rnn_size,
num_layers,
source_sequence_length,
source_vocab_size,
encoding_embedding_size)
# Prepare the target sequences we'll feed to the decoder in training mode
dec_input = process_decoder_input(targets, target_letter_to_int, batch_size)
# Pass encoder state and decoder inputs to the decoders
training_decoder_output, inference_decoder_output = decoding_layer(target_letter_to_int,
decoding_embedding_size,
num_layers,
rnn_size,
target_sequence_length,
max_target_sequence_length,
enc_state,
dec_input)
return training_decoder_output, inference_decoder_output
training_decoder_output 和 inference_decoder_output 模型的输出形式是一样的:
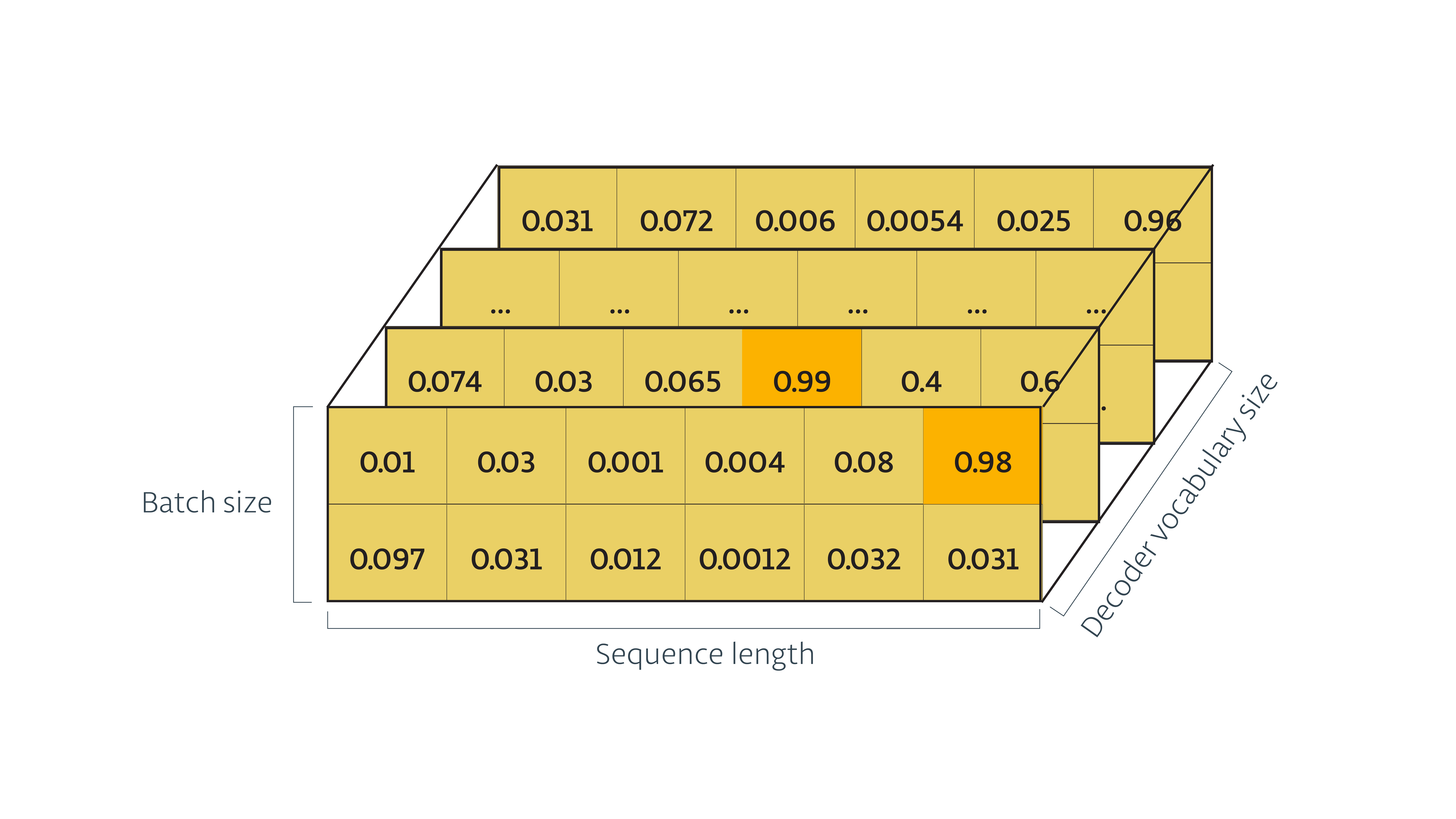
最后,我们使用 tf.contrib.seq2seq.sequence_loss() 来计算损失。
# Build the graph
train_graph = tf.Graph()
# Set the graph to default to ensure that it is ready for training
with train_graph.as_default():
# Load the model inputs
input_data, targets, lr, target_sequence_length, max_target_sequence_length, source_sequence_length = get_model_inputs()
# Create the training and inference logits
training_decoder_output, inference_decoder_output = seq2seq_model(input_data,
targets,
lr,
target_sequence_length,
max_target_sequence_length,
source_sequence_length,
len(source_letter_to_int),
len(target_letter_to_int),
encoding_embedding_size,
decoding_embedding_size,
rnn_size,
num_layers)
# Create tensors for the training logits and inference logits
training_logits = tf.identity(training_decoder_output.rnn_output, 'logits')
inference_logits = tf.identity(inference_decoder_output.sample_id, name='predictions')
# Create the weights for sequence_loss
masks = tf.sequence_mask(target_sequence_length, max_target_sequence_length, dtype=tf.float32, name='masks')
with tf.name_scope("optimization"):
# Loss function
cost = tf.contrib.seq2seq.sequence_loss(
training_logits,
targets,
masks)
# Optimizer
optimizer = tf.train.AdamOptimizer(lr)
# Gradient Clipping
gradients = optimizer.compute_gradients(cost)
capped_gradients = [(tf.clip_by_value(grad, -5., 5.), var) for grad, var in gradients if grad is not None]
train_op = optimizer.apply_gradients(capped_gradients)
batch
我们希望的输出是这样的:
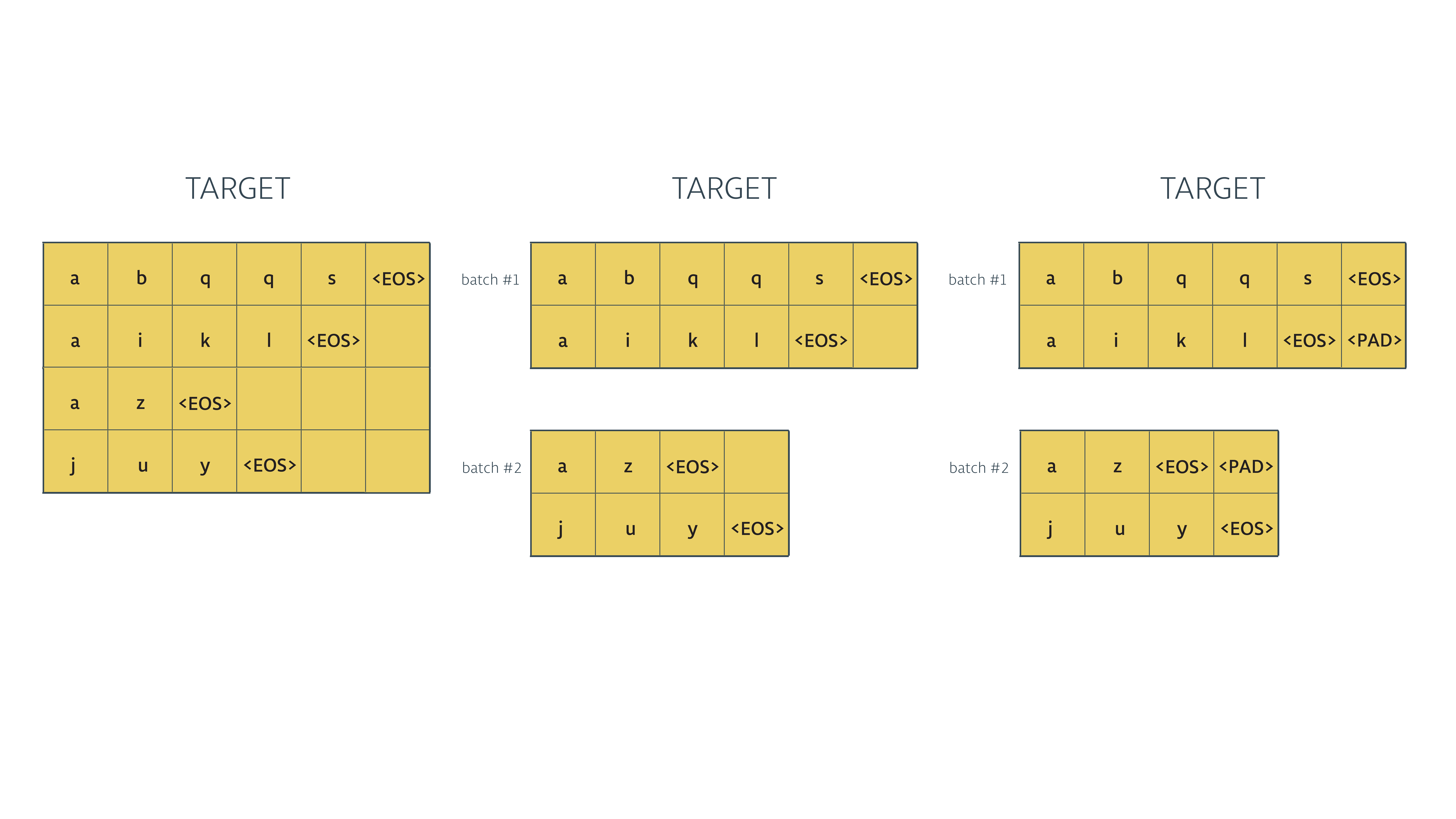
我们希望的输入是这样的:
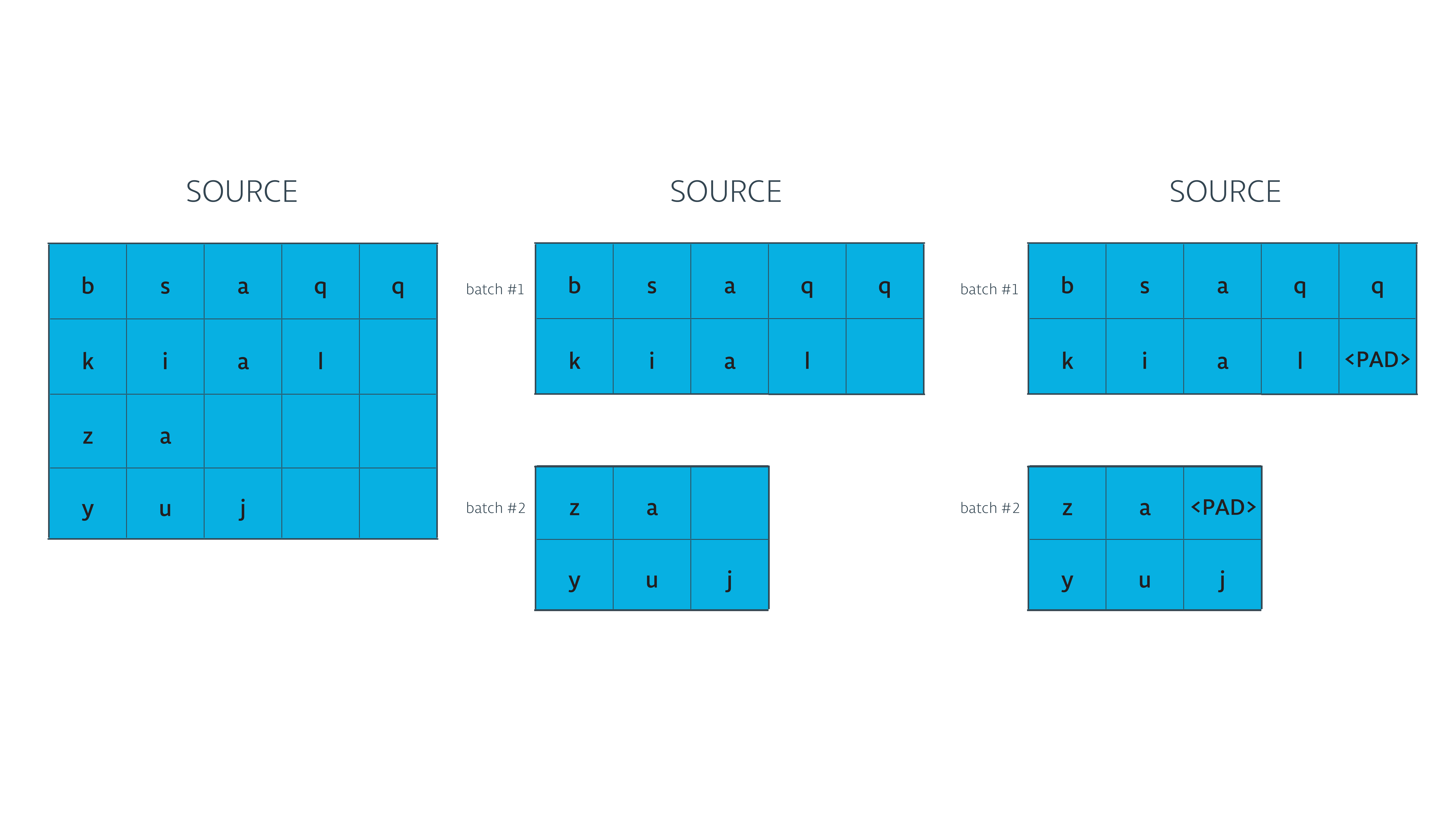
def pad_sentence_batch(sentence_batch, pad_int):
"""Pad sentences with <PAD> so that each sentence of a batch has the same length"""
max_sentence = max([len(sentence) for sentence in sentence_batch])
return [sentence + [pad_int] * (max_sentence - len(sentence)) for sentence in sentence_batch]
def get_batches(targets, sources, batch_size, source_pad_int, target_pad_int):
"""Batch targets, sources, and the lengths of their sentences together"""
for batch_i in range(0, len(sources)//batch_size):
start_i = batch_i * batch_size
sources_batch = sources[start_i:start_i + batch_size]
targets_batch = targets[start_i:start_i + batch_size]
pad_sources_batch = np.array(pad_sentence_batch(sources_batch, source_pad_int))
pad_targets_batch = np.array(pad_sentence_batch(targets_batch, target_pad_int))
# Need the lengths for the _lengths parameters
pad_targets_lengths = []
for target in pad_targets_batch:
pad_targets_lengths.append(len(target))
pad_source_lengths = []
for source in pad_sources_batch:
pad_source_lengths.append(len(source))
yield pad_targets_batch, pad_sources_batch, pad_targets_lengths, pad_source_lengths
训练
# Split data to training and validation sets
train_source = source_letter_ids[batch_size:]
train_target = target_letter_ids[batch_size:]
valid_source = source_letter_ids[:batch_size]
valid_target = target_letter_ids[:batch_size]
(valid_targets_batch, valid_sources_batch, valid_targets_lengths, valid_sources_lengths) = next(get_batches(valid_target, valid_source, batch_size,
source_letter_to_int['<PAD>'],
target_letter_to_int['<PAD>']))
display_step = 20 # Check training loss after every 20 batches
checkpoint = "./best_model.ckpt"
with tf.Session(graph=train_graph) as sess:
sess.run(tf.global_variables_initializer())
for epoch_i in range(1, epochs+1):
for batch_i, (targets_batch, sources_batch, targets_lengths, sources_lengths) in enumerate(
get_batches(train_target, train_source, batch_size,
source_letter_to_int['<PAD>'],
target_letter_to_int['<PAD>'])):
# Training step
_, loss = sess.run(
[train_op, cost],
{input_data: sources_batch,
targets: targets_batch,
lr: learning_rate,
target_sequence_length: targets_lengths,
source_sequence_length: sources_lengths})
# Debug message updating us on the status of the training
if batch_i % display_step == 0 and batch_i > 0:
# Calculate validation cost
validation_loss = sess.run(
[cost],
{input_data: valid_sources_batch,
targets: valid_targets_batch,
lr: learning_rate,
target_sequence_length: valid_targets_lengths,
source_sequence_length: valid_sources_lengths})
print('Epoch {:>3}/{} Batch {:>4}/{} - Loss: {:>6.3f} - Validation loss: {:>6.3f}'
.format(epoch_i,
epochs,
batch_i,
len(train_source) // batch_size,
loss,
validation_loss[0]))
# Save Model
saver = tf.train.Saver()
saver.save(sess, checkpoint)
print('Model Trained and Saved')
Epoch 1/60 Batch 20/77 - Loss: 2.471 - Validation loss: 2.490
Epoch 1/60 Batch 40/77 - Loss: 2.277 - Validation loss: 2.230
Epoch 1/60 Batch 60/77 - Loss: 1.957 - Validation loss: 2.004
Epoch 2/60 Batch 20/77 - Loss: 1.665 - Validation loss: 1.745
Epoch 2/60 Batch 40/77 - Loss: 1.673 - Validation loss: 1.631
Epoch 2/60 Batch 60/77 - Loss: 1.505 - Validation loss: 1.538
Epoch 3/60 Batch 20/77 - Loss: 1.379 - Validation loss: 1.443
Epoch 3/60 Batch 40/77 - Loss: 1.452 - Validation loss: 1.418
Epoch 3/60 Batch 60/77 - Loss: 1.351 - Validation loss: 1.377
Epoch 4/60 Batch 20/77 - Loss: 1.209 - Validation loss: 1.269
Epoch 4/60 Batch 40/77 - Loss: 1.262 - Validation loss: 1.230
Epoch 4/60 Batch 60/77 - Loss: 1.152 - Validation loss: 1.192
Epoch 5/60 Batch 20/77 - Loss: 1.080 - Validation loss: 1.131
Epoch 5/60 Batch 40/77 - Loss: 1.135 - Validation loss: 1.107
Epoch 5/60 Batch 60/77 - Loss: 1.041 - Validation loss: 1.080
Epoch 6/60 Batch 20/77 - Loss: 0.978 - Validation loss: 1.029
Epoch 6/60 Batch 40/77 - Loss: 1.023 - Validation loss: 1.005
Epoch 6/60 Batch 60/77 - Loss: 0.935 - Validation loss: 0.982
Epoch 7/60 Batch 20/77 - Loss: 0.870 - Validation loss: 0.938
Epoch 7/60 Batch 40/77 - Loss: 0.908 - Validation loss: 0.918
Epoch 7/60 Batch 60/77 - Loss: 0.836 - Validation loss: 0.895
Epoch 8/60 Batch 20/77 - Loss: 0.777 - Validation loss: 0.852
Epoch 8/60 Batch 40/77 - Loss: 0.814 - Validation loss: 0.828
Epoch 8/60 Batch 60/77 - Loss: 0.754 - Validation loss: 0.799
Epoch 9/60 Batch 20/77 - Loss: 0.686 - Validation loss: 0.751
Epoch 9/60 Batch 40/77 - Loss: 0.720 - Validation loss: 0.732
Epoch 9/60 Batch 60/77 - Loss: 0.678 - Validation loss: 0.710
Epoch 10/60 Batch 20/77 - Loss: 0.613 - Validation loss: 0.673
Epoch 10/60 Batch 40/77 - Loss: 0.645 - Validation loss: 0.654
Epoch 10/60 Batch 60/77 - Loss: 0.610 - Validation loss: 0.647
Epoch 11/60 Batch 20/77 - Loss: 0.532 - Validation loss: 0.590
Epoch 11/60 Batch 40/77 - Loss: 0.569 - Validation loss: 0.572
Epoch 11/60 Batch 60/77 - Loss: 0.531 - Validation loss: 0.585
Epoch 12/60 Batch 20/77 - Loss: 0.476 - Validation loss: 0.532
Epoch 12/60 Batch 40/77 - Loss: 0.511 - Validation loss: 0.509
Epoch 12/60 Batch 60/77 - Loss: 0.477 - Validation loss: 0.493
Epoch 13/60 Batch 20/77 - Loss: 0.416 - Validation loss: 0.468
Epoch 13/60 Batch 40/77 - Loss: 0.462 - Validation loss: 0.459
Epoch 13/60 Batch 60/77 - Loss: 0.432 - Validation loss: 0.447
Epoch 14/60 Batch 20/77 - Loss: 0.372 - Validation loss: 0.423
Epoch 14/60 Batch 40/77 - Loss: 0.419 - Validation loss: 0.414
Epoch 14/60 Batch 60/77 - Loss: 0.392 - Validation loss: 0.404
Epoch 15/60 Batch 20/77 - Loss: 0.333 - Validation loss: 0.384
Epoch 15/60 Batch 40/77 - Loss: 0.382 - Validation loss: 0.377
Epoch 15/60 Batch 60/77 - Loss: 0.358 - Validation loss: 0.369
Epoch 16/60 Batch 20/77 - Loss: 0.300 - Validation loss: 0.351
Epoch 16/60 Batch 40/77 - Loss: 0.348 - Validation loss: 0.345
Epoch 16/60 Batch 60/77 - Loss: 0.327 - Validation loss: 0.338
Epoch 17/60 Batch 20/77 - Loss: 0.272 - Validation loss: 0.324
Epoch 17/60 Batch 40/77 - Loss: 0.316 - Validation loss: 0.317
Epoch 17/60 Batch 60/77 - Loss: 0.299 - Validation loss: 0.311
Epoch 18/60 Batch 20/77 - Loss: 0.246 - Validation loss: 0.296
Epoch 18/60 Batch 40/77 - Loss: 0.286 - Validation loss: 0.293
Epoch 18/60 Batch 60/77 - Loss: 0.272 - Validation loss: 0.283
Epoch 19/60 Batch 20/77 - Loss: 0.221 - Validation loss: 0.270
Epoch 19/60 Batch 40/77 - Loss: 0.256 - Validation loss: 0.269
Epoch 19/60 Batch 60/77 - Loss: 0.245 - Validation loss: 0.258
Epoch 20/60 Batch 20/77 - Loss: 0.198 - Validation loss: 0.244
Epoch 20/60 Batch 40/77 - Loss: 0.228 - Validation loss: 0.243
Epoch 20/60 Batch 60/77 - Loss: 0.221 - Validation loss: 0.234
Epoch 21/60 Batch 20/77 - Loss: 0.183 - Validation loss: 0.224
Epoch 21/60 Batch 40/77 - Loss: 0.205 - Validation loss: 0.218
Epoch 21/60 Batch 60/77 - Loss: 0.195 - Validation loss: 0.212
Epoch 22/60 Batch 20/77 - Loss: 0.161 - Validation loss: 0.206
Epoch 22/60 Batch 40/77 - Loss: 0.185 - Validation loss: 0.218
Epoch 22/60 Batch 60/77 - Loss: 0.173 - Validation loss: 0.194
Epoch 23/60 Batch 20/77 - Loss: 0.136 - Validation loss: 0.182
Epoch 23/60 Batch 40/77 - Loss: 0.162 - Validation loss: 0.176
Epoch 23/60 Batch 60/77 - Loss: 0.150 - Validation loss: 0.170
Epoch 24/60 Batch 20/77 - Loss: 0.120 - Validation loss: 0.166
Epoch 24/60 Batch 40/77 - Loss: 1.044 - Validation loss: 0.249
Epoch 24/60 Batch 60/77 - Loss: 0.199 - Validation loss: 0.250
Epoch 25/60 Batch 20/77 - Loss: 0.112 - Validation loss: 0.157
Epoch 25/60 Batch 40/77 - Loss: 0.135 - Validation loss: 0.149
Epoch 25/60 Batch 60/77 - Loss: 0.126 - Validation loss: 0.145
Epoch 26/60 Batch 20/77 - Loss: 0.097 - Validation loss: 0.140
Epoch 26/60 Batch 40/77 - Loss: 0.120 - Validation loss: 0.135
Epoch 26/60 Batch 60/77 - Loss: 0.114 - Validation loss: 0.132
Epoch 27/60 Batch 20/77 - Loss: 0.087 - Validation loss: 0.129
Epoch 27/60 Batch 40/77 - Loss: 0.109 - Validation loss: 0.124
Epoch 27/60 Batch 60/77 - Loss: 0.105 - Validation loss: 0.122
Epoch 28/60 Batch 20/77 - Loss: 0.079 - Validation loss: 0.119
Epoch 28/60 Batch 40/77 - Loss: 0.099 - Validation loss: 0.115
Epoch 28/60 Batch 60/77 - Loss: 0.097 - Validation loss: 0.113
Epoch 29/60 Batch 20/77 - Loss: 0.072 - Validation loss: 0.111
Epoch 29/60 Batch 40/77 - Loss: 0.090 - Validation loss: 0.106
Epoch 29/60 Batch 60/77 - Loss: 0.089 - Validation loss: 0.105
Epoch 30/60 Batch 20/77 - Loss: 0.066 - Validation loss: 0.103
Epoch 30/60 Batch 40/77 - Loss: 0.083 - Validation loss: 0.099
Epoch 30/60 Batch 60/77 - Loss: 0.082 - Validation loss: 0.097
Epoch 31/60 Batch 20/77 - Loss: 0.060 - Validation loss: 0.096
Epoch 31/60 Batch 40/77 - Loss: 0.076 - Validation loss: 0.092
Epoch 31/60 Batch 60/77 - Loss: 0.076 - Validation loss: 0.090
Epoch 32/60 Batch 20/77 - Loss: 0.055 - Validation loss: 0.089
Epoch 32/60 Batch 40/77 - Loss: 0.070 - Validation loss: 0.085
Epoch 32/60 Batch 60/77 - Loss: 0.070 - Validation loss: 0.084
Epoch 33/60 Batch 20/77 - Loss: 0.051 - Validation loss: 0.083
Epoch 33/60 Batch 40/77 - Loss: 0.064 - Validation loss: 0.079
Epoch 33/60 Batch 60/77 - Loss: 0.064 - Validation loss: 0.078
Epoch 34/60 Batch 20/77 - Loss: 0.047 - Validation loss: 0.077
Epoch 34/60 Batch 40/77 - Loss: 0.059 - Validation loss: 0.074
Epoch 34/60 Batch 60/77 - Loss: 0.059 - Validation loss: 0.073
Epoch 35/60 Batch 20/77 - Loss: 0.043 - Validation loss: 0.072
Epoch 35/60 Batch 40/77 - Loss: 0.054 - Validation loss: 0.069
Epoch 35/60 Batch 60/77 - Loss: 0.055 - Validation loss: 0.068
Epoch 36/60 Batch 20/77 - Loss: 0.039 - Validation loss: 0.068
Epoch 36/60 Batch 40/77 - Loss: 0.050 - Validation loss: 0.065
Epoch 36/60 Batch 60/77 - Loss: 0.050 - Validation loss: 0.063
Epoch 37/60 Batch 20/77 - Loss: 0.036 - Validation loss: 0.063
Epoch 37/60 Batch 40/77 - Loss: 0.046 - Validation loss: 0.061
Epoch 37/60 Batch 60/77 - Loss: 0.046 - Validation loss: 0.059
Epoch 38/60 Batch 20/77 - Loss: 0.034 - Validation loss: 0.060
Epoch 38/60 Batch 40/77 - Loss: 0.042 - Validation loss: 0.057
Epoch 38/60 Batch 60/77 - Loss: 0.043 - Validation loss: 0.055
Epoch 39/60 Batch 20/77 - Loss: 0.031 - Validation loss: 0.056
Epoch 39/60 Batch 40/77 - Loss: 0.039 - Validation loss: 0.053
Epoch 39/60 Batch 60/77 - Loss: 0.040 - Validation loss: 0.052
Epoch 40/60 Batch 20/77 - Loss: 0.029 - Validation loss: 0.053
Epoch 40/60 Batch 40/77 - Loss: 0.036 - Validation loss: 0.050
Epoch 40/60 Batch 60/77 - Loss: 0.037 - Validation loss: 0.048
Epoch 41/60 Batch 20/77 - Loss: 0.027 - Validation loss: 0.050
Epoch 41/60 Batch 40/77 - Loss: 0.034 - Validation loss: 0.047
Epoch 41/60 Batch 60/77 - Loss: 0.034 - Validation loss: 0.045
Epoch 42/60 Batch 20/77 - Loss: 0.025 - Validation loss: 0.048
Epoch 42/60 Batch 40/77 - Loss: 0.031 - Validation loss: 0.044
Epoch 42/60 Batch 60/77 - Loss: 0.032 - Validation loss: 0.042
Epoch 43/60 Batch 20/77 - Loss: 0.023 - Validation loss: 0.045
Epoch 43/60 Batch 40/77 - Loss: 0.029 - Validation loss: 0.041
Epoch 43/60 Batch 60/77 - Loss: 0.029 - Validation loss: 0.039
Epoch 44/60 Batch 20/77 - Loss: 0.021 - Validation loss: 0.043
Epoch 44/60 Batch 40/77 - Loss: 0.028 - Validation loss: 0.039
Epoch 44/60 Batch 60/77 - Loss: 0.027 - Validation loss: 0.037
Epoch 45/60 Batch 20/77 - Loss: 0.019 - Validation loss: 0.041
Epoch 45/60 Batch 40/77 - Loss: 0.026 - Validation loss: 0.037
Epoch 45/60 Batch 60/77 - Loss: 0.026 - Validation loss: 0.034
Epoch 46/60 Batch 20/77 - Loss: 0.018 - Validation loss: 0.039
Epoch 46/60 Batch 40/77 - Loss: 0.024 - Validation loss: 0.035
Epoch 46/60 Batch 60/77 - Loss: 0.024 - Validation loss: 0.032
Epoch 47/60 Batch 20/77 - Loss: 0.016 - Validation loss: 0.037
Epoch 47/60 Batch 40/77 - Loss: 0.023 - Validation loss: 0.033
Epoch 47/60 Batch 60/77 - Loss: 0.022 - Validation loss: 0.030
Epoch 48/60 Batch 20/77 - Loss: 0.015 - Validation loss: 0.035
Epoch 48/60 Batch 40/77 - Loss: 0.021 - Validation loss: 0.031
Epoch 48/60 Batch 60/77 - Loss: 0.021 - Validation loss: 0.029
Epoch 49/60 Batch 20/77 - Loss: 0.014 - Validation loss: 0.034
Epoch 49/60 Batch 40/77 - Loss: 0.020 - Validation loss: 0.030
Epoch 49/60 Batch 60/77 - Loss: 0.019 - Validation loss: 0.027
Epoch 50/60 Batch 20/77 - Loss: 0.012 - Validation loss: 0.032
Epoch 50/60 Batch 40/77 - Loss: 0.019 - Validation loss: 0.028
Epoch 50/60 Batch 60/77 - Loss: 0.018 - Validation loss: 0.025
Epoch 51/60 Batch 20/77 - Loss: 0.011 - Validation loss: 0.031
Epoch 51/60 Batch 40/77 - Loss: 0.018 - Validation loss: 0.027
Epoch 51/60 Batch 60/77 - Loss: 0.017 - Validation loss: 0.024
Epoch 52/60 Batch 20/77 - Loss: 0.010 - Validation loss: 0.030
Epoch 52/60 Batch 40/77 - Loss: 0.017 - Validation loss: 0.026
Epoch 52/60 Batch 60/77 - Loss: 0.016 - Validation loss: 0.023
Epoch 53/60 Batch 20/77 - Loss: 0.009 - Validation loss: 0.028
Epoch 53/60 Batch 40/77 - Loss: 0.016 - Validation loss: 0.025
Epoch 53/60 Batch 60/77 - Loss: 0.015 - Validation loss: 0.022
Epoch 54/60 Batch 20/77 - Loss: 0.009 - Validation loss: 0.027
Epoch 54/60 Batch 40/77 - Loss: 0.015 - Validation loss: 0.024
Epoch 54/60 Batch 60/77 - Loss: 0.014 - Validation loss: 0.021
Epoch 55/60 Batch 20/77 - Loss: 0.008 - Validation loss: 0.025
Epoch 55/60 Batch 40/77 - Loss: 0.014 - Validation loss: 0.024
Epoch 55/60 Batch 60/77 - Loss: 0.013 - Validation loss: 0.020
Epoch 56/60 Batch 20/77 - Loss: 0.007 - Validation loss: 0.023
Epoch 56/60 Batch 40/77 - Loss: 0.013 - Validation loss: 0.023
Epoch 56/60 Batch 60/77 - Loss: 0.012 - Validation loss: 0.019
Epoch 57/60 Batch 20/77 - Loss: 0.007 - Validation loss: 0.021
Epoch 57/60 Batch 40/77 - Loss: 0.013 - Validation loss: 0.023
Epoch 57/60 Batch 60/77 - Loss: 0.011 - Validation loss: 0.018
Epoch 58/60 Batch 20/77 - Loss: 0.007 - Validation loss: 0.019
Epoch 58/60 Batch 40/77 - Loss: 0.012 - Validation loss: 0.023
Epoch 58/60 Batch 60/77 - Loss: 0.011 - Validation loss: 0.017
Epoch 59/60 Batch 20/77 - Loss: 0.006 - Validation loss: 0.018
Epoch 59/60 Batch 40/77 - Loss: 0.011 - Validation loss: 0.022
Epoch 59/60 Batch 60/77 - Loss: 0.010 - Validation loss: 0.017
Epoch 60/60 Batch 20/77 - Loss: 0.006 - Validation loss: 0.017
Epoch 60/60 Batch 40/77 - Loss: 0.010 - Validation loss: 0.021
Epoch 60/60 Batch 60/77 - Loss: 0.010 - Validation loss: 0.017
Model Trained and Saved
预测
def source_to_seq(text):
'''Prepare the text for the model'''
sequence_length = 7
return [source_letter_to_int.get(word, source_letter_to_int['<UNK>']) for word in text]+ [source_letter_to_int['<PAD>']]*(sequence_length-len(text))
input_sentence = 'hello'
text = source_to_seq(input_sentence)
checkpoint = "./best_model.ckpt"
loaded_graph = tf.Graph()
with tf.Session(graph=loaded_graph) as sess:
# Load saved model
loader = tf.train.import_meta_graph(checkpoint + '.meta')
loader.restore(sess, checkpoint)
input_data = loaded_graph.get_tensor_by_name('input:0')
logits = loaded_graph.get_tensor_by_name('predictions:0')
source_sequence_length = loaded_graph.get_tensor_by_name('source_sequence_length:0')
target_sequence_length = loaded_graph.get_tensor_by_name('target_sequence_length:0')
#Multiply by batch_size to match the model's input parameters
answer_logits = sess.run(logits, {input_data: [text]*batch_size,
target_sequence_length: [len(text)]*batch_size,
source_sequence_length: [len(text)]*batch_size})[0]
pad = source_letter_to_int["<PAD>"]
print('Original Text:', input_sentence)
print('\nSource')
print(' Word Ids: {}'.format([i for i in text]))
print(' Input Words: {}'.format(" ".join([source_int_to_letter[i] for i in text])))
print('\nTarget')
print(' Word Ids: {}'.format([i for i in answer_logits if i != pad]))
print(' Response Words: {}'.format(" ".join([target_int_to_letter[i] for i in answer_logits if i != pad])))
INFO:tensorflow:Restoring parameters from ./best_model.ckpt
Original Text: hello
Source
Word Ids: [14, 4, 27, 27, 21, 0, 0]
Input Words: h e l l o <PAD> <PAD>
Target
Word Ids: [4, 14, 27, 27, 21, 3]
Response Words: e h l l o <EOS>