单词嵌入
29 Apr 2018 | deep-learning |Skip-gram word2vec
这篇文章主要是基于skip-gram 架构,使用TensorFlow来实现单词嵌入,在自然语言处理或机器翻译中是很有效的。文章来源于udacity
参考文章
- A really good conceptual overview of word2vec from Chris McCormick
- First word2vec paper from Mikolov et al.
- NIPS paper with improvements for word2vec also from Mikolov et al.
- An implementation of word2vec from Thushan Ganegedara
- TensorFlow word2vec tutorial
单词嵌入
当你处理文本中的单词时,你最终会有成千上万的类要预测,每个单词一个。使用one-hot编码是低效的,其中只有一个是1,而其他都是0。尤其是进行矩阵运算时,效率就更低了。
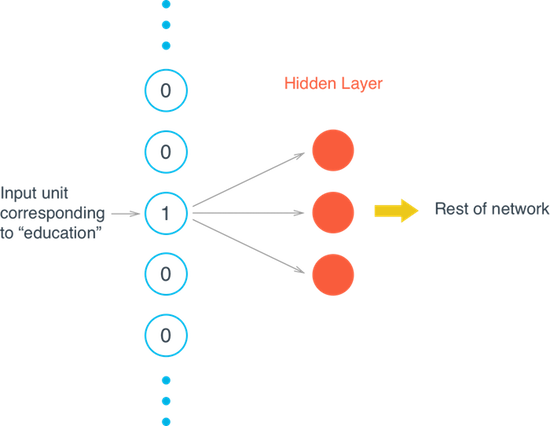 为了解决这个问题和提高网络的效率,我们使用单词嵌入。所谓的嵌入其实就是一个全连接操作,我们把这一层叫做嵌入层,其中的权重叫做嵌入权重。
为了解决这个问题和提高网络的效率,我们使用单词嵌入。所谓的嵌入其实就是一个全连接操作,我们把这一层叫做嵌入层,其中的权重叫做嵌入权重。
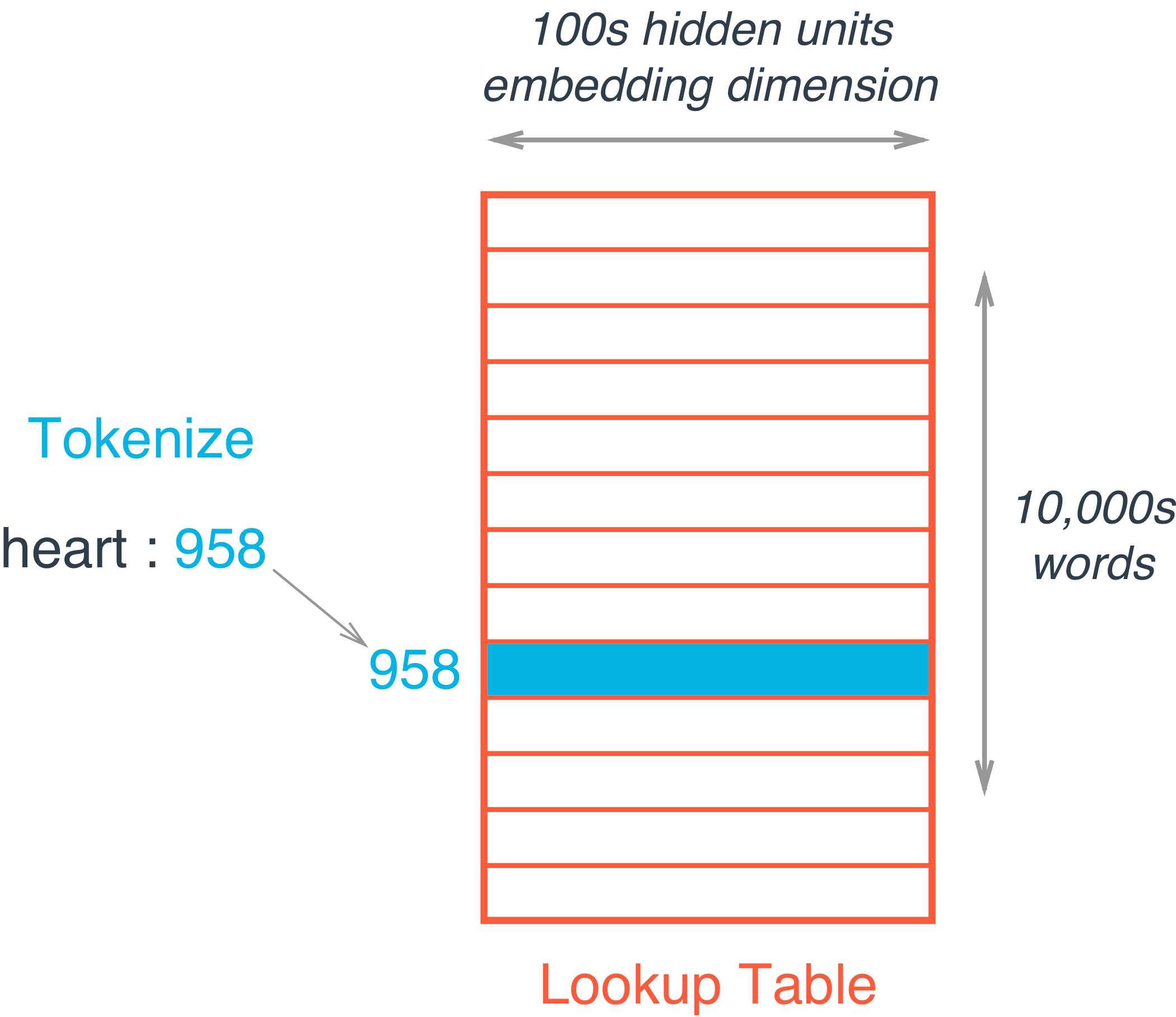
 我们并不进行矩阵乘法操作,而是将权重矩阵作为一个查找表。将所有要输入的单词编码为一个整数,比如
我们并不进行矩阵乘法操作,而是将权重矩阵作为一个查找表。将所有要输入的单词编码为一个整数,比如heart被编码为958,mind被编码为18094。然后获取单词heart所对应的隐藏层的值,也就是嵌入矩阵的第958行,那么这一行所对应的数据就是这个单词所包含的信息。这个处理过程叫做embedding lookup ,隐藏单元的个数叫做 embedding dimension。当然,这个权重系数与其他权重一样也会被网络进行训练。
Word2Vec
通过一个矢量来表示一个单词的方法叫做Word2Vec,这种方式是非常有效的,这个矢量包含了单词的语义信息。一个单词会出现在相似的上下文中,比如black,white,red它们的矢量形式将会非常接近。实现word2vec有两种结构,一种是CBOW(多对一),一种是Skip-gram(一对多)
 在这次的实验中,我们使用的是
在这次的实验中,我们使用的是Skip-gram结构,它比CBOW结构更有效率。我们传入一个单词,想要得到的输出是与这个单词相近的多个单词。接下来,我们将会构建网络并进行训练。
import time
import numpy as np
import tensorflow as tf
import utils
此次,我们所使用的数据集是text8 dataset。
from urllib.request import urlretrieve
from os.path import isfile, isdir
from tqdm import tqdm
import zipfile
dataset_folder_path = 'data'
dataset_filename = 'text8.zip'
dataset_name = 'Text8 Dataset'
class DLProgress(tqdm):
last_block = 0
def hook(self, block_num=1, block_size=1, total_size=None):
self.total = total_size
self.update((block_num - self.last_block) * block_size)
self.last_block = block_num
if not isfile(dataset_filename):
with DLProgress(unit='B', unit_scale=True, miniters=1, desc=dataset_name) as pbar:
urlretrieve(
'http://mattmahoney.net/dc/text8.zip',
dataset_filename,
pbar.hook)
if not isdir(dataset_folder_path):
with zipfile.ZipFile(dataset_filename) as zip_ref:
zip_ref.extractall(dataset_folder_path)
with open('data/text8') as f:
text = f.read()
Preprocessing
在这里,将修改文本以使训练更容易。“预处理”功能将所有标点符号转换为标记,比如.将变为<PERIOD> 。同时还将删除数据集中显示五次或更少次数的单词。这将大大减少由于数据中的噪声引起的问题,并提高矢量表示的质量。当然这些你都可以直接实现。
words = utils.preprocess(text)
print(words[:30])
['anarchism', 'originated', 'as', 'a', 'term', 'of', 'abuse', 'first', 'used', 'against', 'early', 'working', 'class', 'radicals', 'including', 'the', 'diggers', 'of', 'the', 'english', 'revolution', 'and', 'the', 'sans', 'culottes', 'of', 'the', 'french', 'revolution', 'whilst']
print("Total words: {}".format(len(words)))
print("Unique words: {}".format(len(set(words))))
Total words: 16680599
Unique words: 63641
接下来,将创建两个字典,用于表示单词所对应的整数和整数所对应的单词。字典中的顺序是降序的,也就是说,出现最高频率的单词the的整数值是0,次高频率的整数值是1。int_words表示全部的words对应的整数值。
vocab_to_int, int_to_vocab = utils.create_lookup_tables(words)
int_words = [vocab_to_int[word] for word in words]
print(vocab_to_int['the'])
print(int_to_vocab[0])
print(int_words[0])
print(words[0])
print(vocab_to_int['anarchism'])
print(len(int_words))
0
the
5242
anarchism
5242
16680599
子采样
有些单词的出现并不能提供有用的上下文信息,比如the,of,for,如果我们忽略了这些单词,将可以有效的减少数据集中的噪声,提高网络的训练速度和更好的矢量表示。一个单词被忽略的概率是:
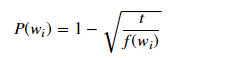
其中t是一个阈值,f(w)是单词出现的频率
from collections import Counter
import random
threshold = 1e-5
word_counts = Counter(int_words)
total_count = len(int_words)
freqs = {word: count/total_count for word, count in word_counts.items()}
p_drop = {word: 1 - np.sqrt(threshold/freqs[word]) for word in word_counts}
train_words = [word for word in int_words if random.random() < (1 - p_drop[word])]
print(train_words[:10])
print(len(train_words))
[5242, 3080, 127, 10586, 27770, 15175, 58343, 854, 3581, 10768]
4629165
创建批次
现在,我们需要以恰当的形式输入到网络中,我们使用的是Skip-gram架构,即对于文本中的每个单词,我们想要抓取它周围的好几个词,这个大小我们设置为C。
你可以参考: Mikolov et al.:
“Since the more distant words are usually less related to the current word than those close to it, we give less weight to the distant words by sampling less from those words in our training examples… If we choose $C = 5$, for each training word we will select randomly a number $R$ in range $< 1; C >$, and then use $R$ words from history and $R$ words from the future of the current word as correct labels.”
def get_target(words, idx, window_size=5):
''' Get a list of words in a window around an index. '''
R = np.random.randint(1, window_size+1)
start = idx - R if (idx - R) > 0 else 0
stop = idx + R
target_words = set(words[start:idx] + words[idx+1:stop+1])
return list(target_words)
创建批次用于网络的输入
def get_batches(words, batch_size, window_size=5):
''' Create a generator of word batches as a tuple (inputs, targets) '''
n_batches = len(words)//batch_size
# only full batches
words = words[:n_batches*batch_size]
for idx in range(0, len(words), batch_size):
x, y = [], []
batch = words[idx:idx+batch_size]
for ii in range(len(batch)):
batch_x = batch[ii]
batch_y = get_target(batch, ii, window_size)
y.extend(batch_y)
x.extend([batch_x]*len(batch_y))
yield x, y
test_word=[1,2,3,4,5,6,7,8,9]
test_1 = get_batches(test_word,4)
x ,y = next(test_1)
print(x)
print(np.array(y)[:,None])
[1, 1, 1, 2, 2, 3, 3, 3, 4]
[[2]
[3]
[4]
[1]
[3]
[1]
[2]
[4]
[3]]
构建图
Chris McCormick’s blog博客中的网络架构:
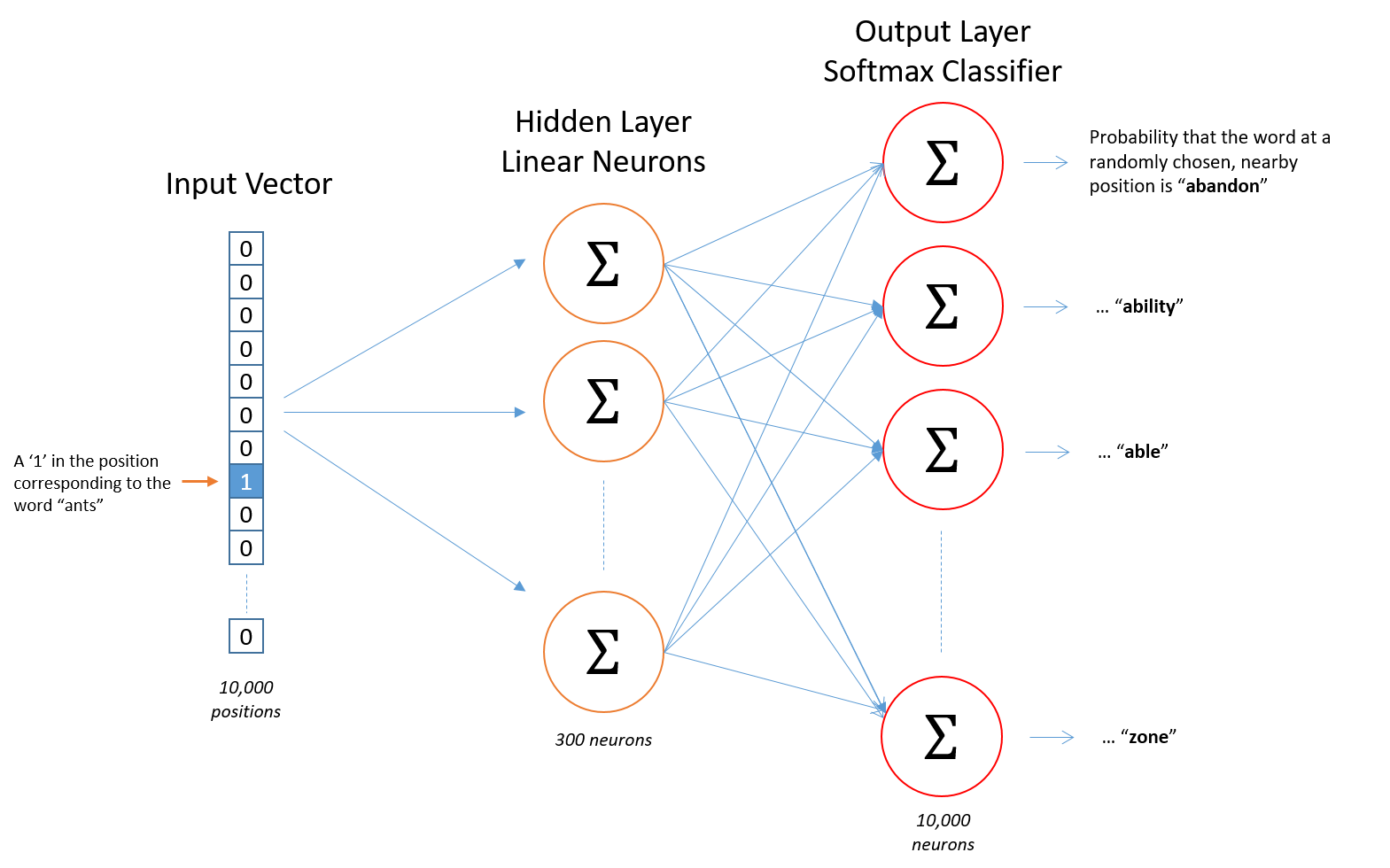
输入单词以独立热编码的形式进行输入,然后进过隐藏层,再进过softmax层作为预测。而我们想要训练隐藏层的权重矩阵来找到最有效的单词表示,所以我们会忽略输出层,我们并不做预测,只是想得到权重矩阵。
train_graph = tf.Graph()
with train_graph.as_default():
inputs = tf.placeholder(tf.int32, [None], name='inputs')
labels = tf.placeholder(tf.int32, [None, None], name='labels')
嵌入
嵌入矩阵的大小就是所有单词的大小,比如,你有10,000个单词和300个隐藏单元(隐藏单元的个数,自己设置就好),那么嵌入矩阵的大小就是10000 * 300.
print(len(int_to_vocab))
63641
n_vocab = len(int_to_vocab)
n_embedding = 200 # Number of embedding features
with train_graph.as_default():
embedding = tf.Variable(tf.random_uniform((n_vocab, n_embedding), -1, 1))# 创建权重矩阵,并随机初始化
embed = tf.nn.embedding_lookup(embedding, inputs)#得到word2vec
负采样
在进行更新的时候,我们更新全部正确标签的值,但是只更新少量不正确的值.如何选取少量不正确的值的方式叫做负采样 “negative sampling”. TensorFlow提供了这样的方法 tf.nn.sampled_softmax_loss.
# Number of negative labels to sample
n_sampled = 100
with train_graph.as_default():
softmax_w = tf.Variable(tf.truncated_normal((n_vocab, n_embedding), stddev=0.1))
softmax_b = tf.Variable(tf.zeros(n_vocab))
# Calculate the loss using negative sampling
loss = tf.nn.sampled_softmax_loss(softmax_w, softmax_b,
labels, embed,
n_sampled, n_vocab)
cost = tf.reduce_mean(loss)
optimizer = tf.train.AdamOptimizer().minimize(cost)
验证
我们选取常用的与不常用的单词,单词所包含的信息相近那么他们也就靠的的很近。
with train_graph.as_default():
## From Thushan Ganegedara's implementation
valid_size = 16 # Random set of words to evaluate similarity on.
valid_window = 100
# pick 8 samples from (0,100) and (1000,1100) each ranges. lower id implies more frequent
valid_examples = np.array(random.sample(range(valid_window), valid_size//2))
valid_examples = np.append(valid_examples,
random.sample(range(1000,1000+valid_window), valid_size//2))
valid_dataset = tf.constant(valid_examples, dtype=tf.int32)
# We use the cosine distance:
norm = tf.sqrt(tf.reduce_sum(tf.square(embedding), 1, keep_dims=True))
normalized_embedding = embedding / norm
valid_embedding = tf.nn.embedding_lookup(normalized_embedding, valid_dataset)
similarity = tf.matmul(valid_embedding, tf.transpose(normalized_embedding))
# If the checkpoints directory doesn't exist:
!mkdir checkpoints
epochs = 10
batch_size = 1000
window_size = 10
with train_graph.as_default():
saver = tf.train.Saver()
with tf.Session(graph=train_graph) as sess:
iteration = 1
loss = 0
sess.run(tf.global_variables_initializer())
for e in range(1, epochs+1):
batches = get_batches(train_words, batch_size, window_size)
start = time.time()
for x, y in batches:
feed = {inputs: x,
labels: np.array(y)[:, None]}
train_loss, _ = sess.run([cost, optimizer], feed_dict=feed)
loss += train_loss
if iteration % 100 == 0:
end = time.time()
print("Epoch {}/{}".format(e, epochs),
"Iteration: {}".format(iteration),
"Avg. Training loss: {:.4f}".format(loss/100),
"{:.4f} sec/batch".format((end-start)/100))
loss = 0
start = time.time()
if iteration % 1000 == 0:
# note that this is expensive (~20% slowdown if computed every 500 steps)
sim = similarity.eval()
for i in range(valid_size):
valid_word = int_to_vocab[valid_examples[i]]
top_k = 8 # number of nearest neighbors
nearest = (-sim[i, :]).argsort()[1:top_k+1]
log = 'Nearest to %s:' % valid_word
for k in range(top_k):
close_word = int_to_vocab[nearest[k]]
log = '%s %s,' % (log, close_word)
print(log)
iteration += 1
save_path = saver.save(sess, "checkpoints/text8.ckpt")
embed_mat = sess.run(normalized_embedding)
with train_graph.as_default():
saver = tf.train.Saver()
with tf.Session(graph=train_graph) as sess:
saver.restore(sess, tf.train.latest_checkpoint('checkpoints'))
embed_mat = sess.run(embedding)
单词向量可视化
我们使用T-SNE来可视化我们的高维数据,T-SNE可以把高维变成二维同时保留信息。参考博文: this post from Christopher Olah
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
viz_words = 500
tsne = TSNE()
embed_tsne = tsne.fit_transform(embed_mat[:viz_words, :])
fig, ax = plt.subplots(figsize=(14, 14))
for idx in range(viz_words):
plt.scatter(*embed_tsne[idx, :], color='steelblue')
plt.annotate(int_to_vocab[idx], (embed_tsne[idx, 0], embed_tsne[idx, 1]), alpha=0.7)
