自编码器
14 Apr 2018 | deep-learning |简单的自编码器
我们将会构建一个简单的自编码器来压缩MNIST数据集。通过编码器传入输入数据,它会压缩输入数据,然后,被压缩的数据再传给解码器,它重构输入数据。通常使用神经网络来构建编码器与解码器,然后进行数据训练。

%matplotlib inline
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('MNIST_data', validation_size=0)
Successfully downloaded train-images-idx3-ubyte.gz 9912422 bytes.
Extracting MNIST_data/train-images-idx3-ubyte.gz
Successfully downloaded train-labels-idx1-ubyte.gz 28881 bytes.
Extracting MNIST_data/train-labels-idx1-ubyte.gz
Successfully downloaded t10k-images-idx3-ubyte.gz 1648877 bytes.
Extracting MNIST_data/t10k-images-idx3-ubyte.gz
Successfully downloaded t10k-labels-idx1-ubyte.gz 4542 bytes.
Extracting MNIST_data/t10k-labels-idx1-ubyte.gz
通过上面将导入数据集,我们可以查看一下其中的一张图片。
img = mnist.train.images[2]
plt.imshow(img.reshape((28, 28)), cmap='Greys_r')
<matplotlib.image.AxesImage at 0x11abae4a8>

首先我们把图像扁平化长度为784的一个向量,然后传入代自编码器进行训练。这些值已经进过归一化处理了,值都在0到1之间。自编码器中的激活函数使用的是ReLU,它用于压缩输入,然后经过解码器,因为我们的值都是在0到1之间,所以最后我们使用了sigmoid作为激活函数。
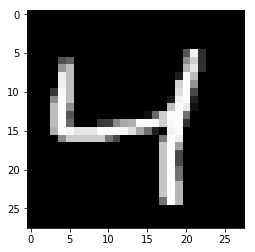
# Size of the encoding layer (the hidden layer)
encoding_dim = 32
image_size = mnist.train.images.shape[1]
inputs_ = tf.placeholder(tf.float32, (None, image_size), name='inputs')
targets_ = tf.placeholder(tf.float32, (None, image_size), name='targets')
# Output of hidden layer
encoded = tf.layers.dense(inputs_, encoding_dim, activation=tf.nn.relu)
# Output layer logits
logits = tf.layers.dense(encoded, image_size, activation=None)
# Sigmoid output from
decoded = tf.nn.sigmoid(logits, name='output')
loss = tf.nn.sigmoid_cross_entropy_with_logits(labels=targets_, logits=logits)
cost = tf.reduce_mean(loss)
opt = tf.train.AdamOptimizer(0.001).minimize(cost)
训练
# Create the session
sess = tf.Session()
epochs = 20
batch_size = 200
sess.run(tf.global_variables_initializer())
for e in range(epochs):
for ii in range(mnist.train.num_examples//batch_size):
batch = mnist.train.next_batch(batch_size)
feed = {inputs_: batch[0], targets_: batch[0]}
batch_cost, _ = sess.run([cost, opt], feed_dict=feed)
print("Epoch: {}/{}...".format(e+1, epochs),
"Training loss: {:.4f}".format(batch_cost))
结果检验
fig, axes = plt.subplots(nrows=2, ncols=10, sharex=True, sharey=True, figsize=(20,4))
in_imgs = mnist.test.images[:10]
reconstructed, compressed = sess.run([decoded, encoded], feed_dict={inputs_: in_imgs})
for images, row in zip([in_imgs, reconstructed], axes):
for img, ax in zip(images, row):
ax.imshow(img.reshape((28, 28)), cmap='Greys_r')
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
fig.tight_layout(pad=0.1)

sess.close()
接下来
我们在这里处理的是图像,因此我们可以使用卷积层获得更好的性能。接下来,我们将构建一个更好的具有卷积层的自动编码器。 实际上,与JPEGs和MP3等典型方法相比,自动编码器在压缩方面并不擅长。但是,它们可以被用来降低噪音。